深入 NVIDIA GPU:高性能 matmul 内核的结构解析(译)
译者注: 本文翻译自 Aleksa Gordić 的技术博客文章。原文链接:https://www.aleksagordic.com/blog/matmul
这是一篇深入讲解 NVIDIA GPU 矩阵乘法内核优化的技术文章,从硬件架构、汇编语言到 SOTA 异步内核设计,内容详实且具有很强的实践指导意义。翻译过程中已尽力保持原文的技术准确性和可读性,如有疏漏之处,欢迎指正。
从 GPU 架构与 PTX/SASS,到 warp-tiling 与深度异步 Tensor Core 流水线
2025 年 9 月 29 日
在本文中,我将循序渐进地介绍所有支撑当前最先进(SOTA)NVIDIA GPU 矩阵乘法(matmul)内核的核心硬件概念与编程技术。
为什么是 matmul? 无论是在训练还是推理阶段,Transformer 模型的大部分 FLOPs 都消耗在 matmul 上(MLP 中的线性层、注意力中的 QKV 投影、输出投影等)。这些操作具有高度可并行性(embarrassingly parallel),因此天然适合 GPU。更重要的是,一旦你理解了 matmul 内核的工作方式,你就掌握了设计几乎任何高性能 GPU 内核所需的工具箱。
本文分为四个部分:
- NVIDIA GPU 架构基础:global memory、shared memory、L1/L2 cache、电源限频(power throttling)对 SoL 的影响等
- GPU 汇编语言:SASS 与 PTX
- 设计接近 SOTA 的同步 matmul 内核:warp-tiling 方法
- 在 Hopper 上设计 SOTA 异步 matmul 内核:利用 Tensor Core、TMA、计算与访存重叠、Hilbert 曲线等
我的目标是让这篇文章具有自洽性:细节足够扎实,可以独立成文;同时又足够简洁,不至于变成一本教科书。
这是一个更大系列的第一部分。在接下来的文章中,我(理想情况下)计划讨论:
- 在 Blackwell GPU 上设计 SOTA matmul 内核
- 通过 microbenchmark 实验探索 GPU 架构
- 设计 SOTA 多 GPU 内核
- 揭开内存一致性模型的神秘面纱(它之于 GPU,就像 tokenizer 之于大模型:一个让整个系统悄然运转的关键组件,却依然让大多数开发者困惑)
NVIDIA GPU 架构基础
要编写高性能的 GPU 内核,你必须对硬件建立一个清晰而准确的“心理模型”(mental model)。随着我们逐步深入硬件架构,这一点会很快变得显而易见。
本文将聚焦于 Hopper H100 GPU。如果你对 Hopper 有深入理解,那么将这些知识迁移到未来架构(Blackwell、Rubin)或更早架构(Ampere、Volta)都会变得相对容易。
从最高层面来看,GPU 主要执行两类核心任务:
- 搬运与存储数据(memory system)
- 对数据执行有效计算(compute pipelines)
下面的 H100 框图正体现了这种划分:蓝色部分表示内存或数据移动组件,红色部分表示计算(高功耗)单元。
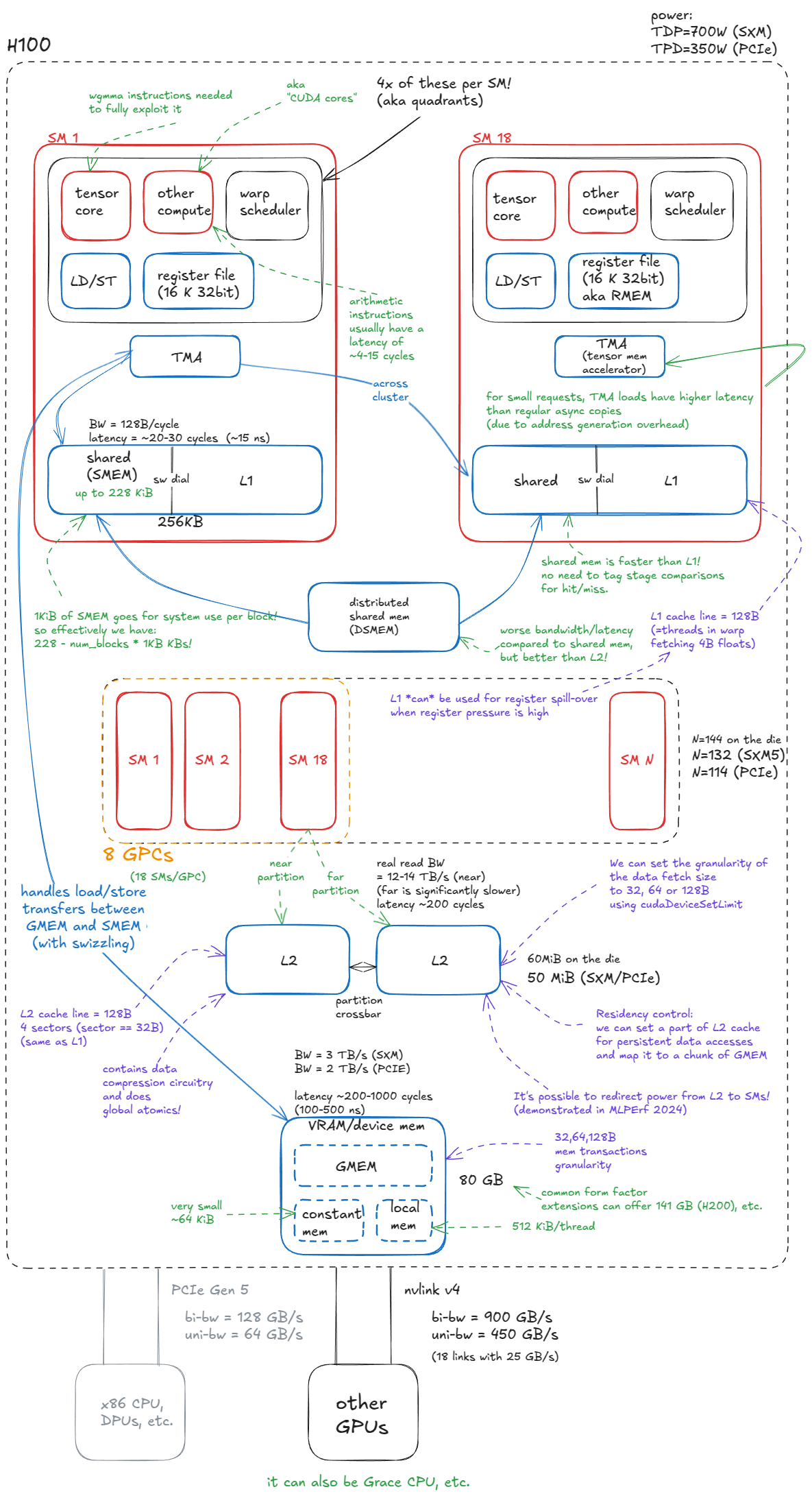
Figure 1: Model of the NVIDIA Hopper H100 GPU
Memory
GPU 的内存系统具有高度分层结构,这一点与 CPU 架构非常相似。
这种层次结构由物理规律与电路设计所决定:SRAM 单元更快但面积更大(实现高速所需的控制电路会增加芯片面积),而 DRAM 单元更小、更高密度,但速度更慢。结果就是,快速内存容量小且昂贵,而慢速内存可以提供更大的容量。我们稍后会更详细地介绍 DRAM 单元与 DRAM 内存。
容量与延迟之间的这种权衡,正是 cache 层次结构存在的根本原因。在理想世界中,每个计算单元都能紧邻一个容量巨大的超高速内存池。然而在物理上这是不可能的,因此 GPU 设计者采取折中方案:在计算单元附近放置少量快速内存,并由更远处、容量更大的慢速内存作为后盾。这种组织方式最大化了整体系统吞吐率。
GPU 的内存系统包括:
- Device memory(VRAM)。在 CUDA 术语中,“device memory” 指的是片外 DRAM —— 物理上与 GPU die 分离,但封装在同一块板卡上 —— 以堆叠式 HBM 的形式实现。它承载 global memory(GMEM)、每线程的“local” memory(寄存器溢出空间)等。
- L2 cache。一个由 SRAM 构建的大型 k 路组相联 cache。它在物理上被划分为两个分区;每个 SM 直接连接其中一个分区,并通过 crossbar 间接访问另一个分区。
- Distributed shared memory(DSMEM)。物理上彼此接近的一组 SM(一个 GPC)所拥有的 shared memory(SMEM)的汇聚。
- L1 cache 与 Shared memory
- L1 cache。每个 SM 私有的较小型 k 路组相联 SRAM cache。
- Shared memory(SMEM)。由程序员管理的片上内存。SMEM 与 L1 共享同一物理存储空间,其比例分配可以通过软件配置。
- Register file(RMEM)。速度最快的存储单元,位于计算单元附近。寄存器为线程私有。与 CPU 相比,GPU 拥有数量多得多的寄存器,而且 RMEM 的总容量与 L1/SMEM 合计容量处于同一量级。
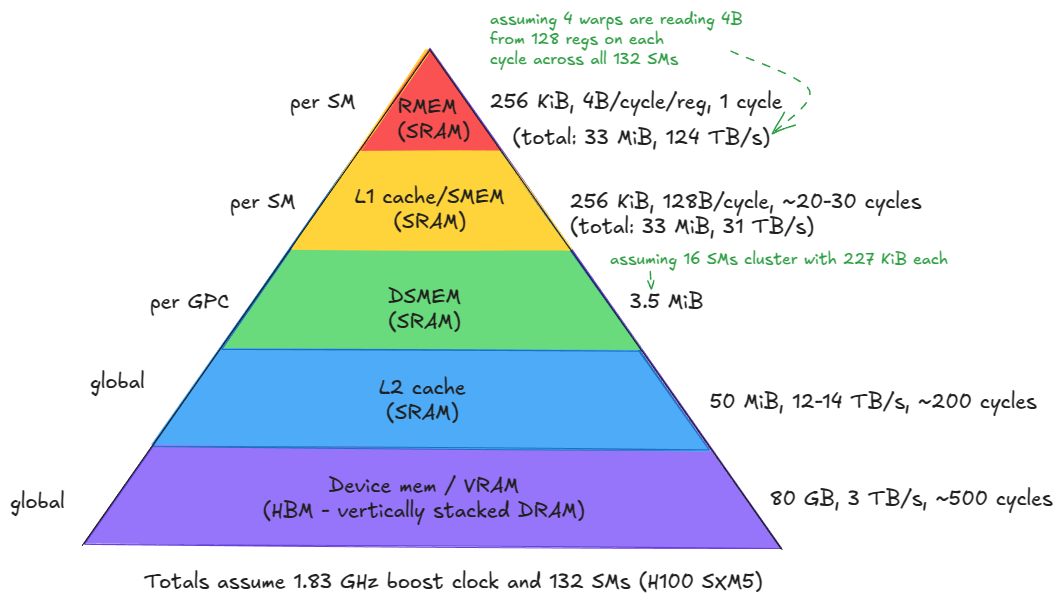
Figure 2: Memory hierarchy of the H100 (SXM5) GPU
📝Note:
还有一些更小的指令 cache,以及 constant memory 等组件,这里暂不讨论,因为它们对理解核心机制并非关键。
从 device memory 一直到寄存器(层级 1–5),可以看到一个明显趋势:带宽以数量级提升,而延迟与容量则以类似的数量级下降。
由此可以直接得出两个重要结论:
- 尽量将最频繁访问的数据放在尽可能靠近计算单元的位置。
- 尽量减少对层次结构底层(尤其是 device memory / GMEM)的访问。
另一个值得注意的组件是 Tensor Memory Accelerator(TMA),它在 Hopper 中首次引入。TMA 支持 global memory 与 shared memory 之间的异步数据传输,也支持 cluster 内部 shared memory 之间的传输。此外,它还支持 swizzling 以减少 bank conflict —— 这些细节我们将在合适的时机(双关)展开。
Compute
从内存转向计算,最基本的计算单元是 streaming multiprocessor(SM)。Hopper H100(SXM5)总共集成了 132 个 SM。
SM 被组织为 graphics processing cluster(GPC):每个 GPC 包含 18 个 SM,整块 GPU 上共有 8 个 GPC。其中 4 个 GPC 直接连接到一个 L2 分区,另外 4 个连接到第二个分区。
📝Notes:
GPC 也是 CUDA 中 thread-block cluster 抽象所对应的硬件单元 —— 我们稍后会回到编程模型。
有一点需要说明:前面提到每个 GPC 有 18 个 SM,那么 8 个 GPC 应该是 144 个 SM。但 SXM/PCIe 形态的产品实际上只开放 132 或 114 个 SM。原因在于 18 × 8 仅适用于完整的 GH100 die,而在实际产品中会熔断部分 SM。这对我们在编写内核时如何选择 cluster 配置有直接影响,例如 cluster 跨越超过 2 个 SM 时,就无法使用全部 SM。
另外,“graphics” 在 GPC 中只是历史遗留术语。在现代服务器级 GPU 中,这些 cluster 实际上只承担计算与 AI 加速功能,而不再是图形引擎。某种意义上说,去掉 G,它们就是 AI 加速器。
除了前面提到的 L1/SMEM/TMA/RMEM(都物理位于 SM 内部)之外,每个 SM 还包含:
- Tensor Cores。用于在小 tile 上执行矩阵乘法(例如
64x16 @ 16x256)的专用单元,具有极高吞吐率。大型矩阵乘法会被拆解为大量这样的 tile 运算,因此高效利用它们是达到峰值性能的关键。 - CUDA cores 与 SFUs。所谓“CUDA cores”(营销术语)执行标准浮点运算,例如 FMA(fused multiply-add:
c = a * b + c)。Special Function Units(SFUs)执行超越函数如sin、cos、exp、log,以及代数函数如sqrt、rsqrt等。 - Load/Store(LD/ST)单元。负责执行 load/store 指令的电路,与 TMA 引擎互补。
- Warp 调度器(Warp schedulers)。每个 SM 内包含调度器,用于为 32 线程一组(即 warp)发射指令。每个 warp 调度器每个 cycle 可以发射一条 warp 指令。
每个 SM 在物理上被划分为四个象限,每个象限包含上述计算单元的一部分。
这带来了一个重要认知:
📝Parallelism vs Concurrency
一个 SM 在同一个 cycle 内,最多只能同时从 4 个 warp 发射指令(即最多 128 个线程在该 cycle 内真正并行执行)。
但是,一个 SM 最多可以驻留 2048 个并发线程(64 个 warp)。这些 warp 常驻在 SM 上,并在时间维度上被调度进出,以隐藏内存与流水线延迟。
换句话说,指令级并行度(每个 cycle 真正开始执行指令的线程数)在每个 SM 上最多为 128 线程,而并发度(被调度器追踪、具备执行资格的线程数)可以达到 2048 线程。
Speed of light 与 power throttling
既然我们购买 NVIDIA GPU 是为了计算能力,那么一个自然问题是:GPU 的计算上限是多少?这通常被称为 “speed of light”(SoL)性能,即由芯片物理特性所决定的理论上限。
不同数据类型对应不同的上限。在 LLM 训练中,bfloat16(bf16)近年来占主导地位,不过 fp8 和 4-bit 格式也变得越来越重要(在推理中,fp8 已相当常见)。
峰值吞吐率的计算公式为:
perf = freq_clk_max * num_tc * flop_per_tc_per_clk
换句话说:最大时钟频率 × Tensor Core 数量 × 每个 Tensor Core 每个 cycle 的 FLOPs。
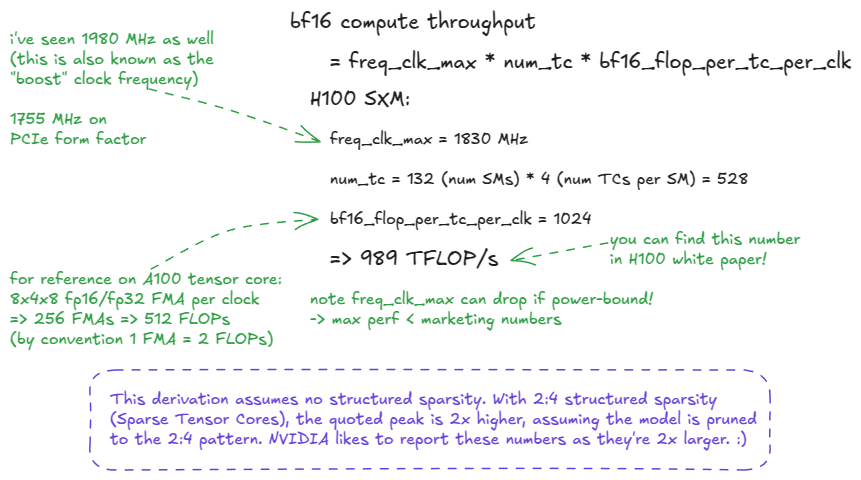
Figure 3: H100 SXM5 BF16 speed-of-light derivation
📝FLOP vs FLOPs vs FLOPS vs FLOP/s
- FLOP = 单次浮点运算
- FLOP/s = 吞吐率单位:每秒浮点运算次数
- FLOPs(小写 s)= FLOP 的复数形式
- FLOPS(全大写)常被误用为吞吐率,但严格来说应读作 “FLOPs”。将 FLOPS 当作 FLOP/s 使用是 SLOP! :)
我在上图中留了一个提示:“speed of light” 实际上并不是常数(类比在这里显然有点失效)。
在实践中,峰值吞吐率取决于实际时钟频率,而时钟频率会受到功耗或温度限制(power / thermal throttling)的影响。如果 GPU 时钟下降,那么有效的 “speed of light” 也会随之下降。
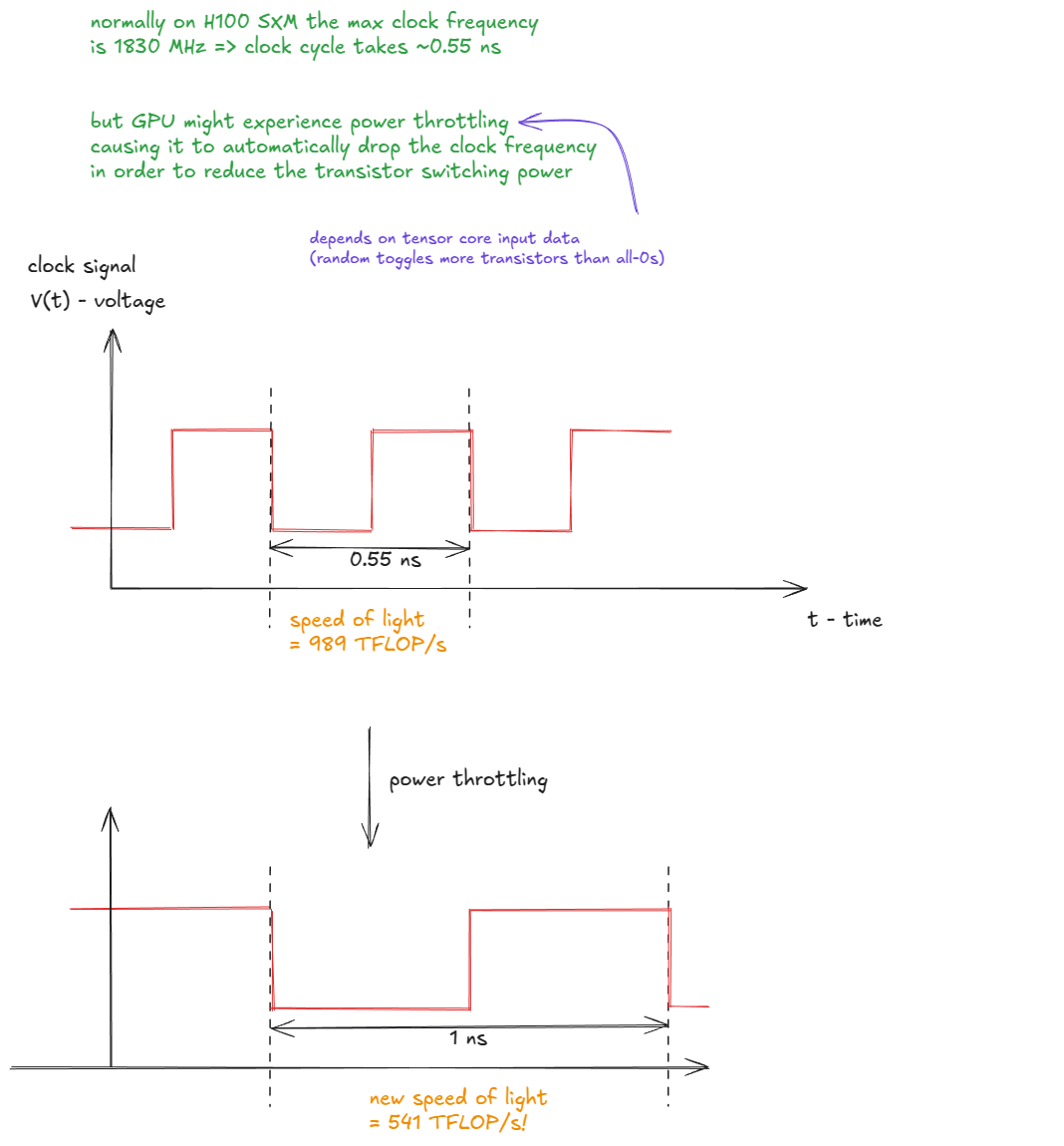
Figure 4: Power throttling reduces clock frequency and lowers the effective “speed of light”
📝Further reading:
目前我们所需的硬件细节就介绍到这里。
接下来,我们将把注意力转向 CUDA 编程模型,然后再进一步深入硬件细节,最终回到 CUDA C++ 的世界。
CUDA 编程模型
CUDA 编程模型天然映射到 GPU 的硬件与内存层次结构。
核心抽象包括:
- thread
- warp(32 threads)
- thread block
- thread block cluster
- grid(由 thread blocks 或 clusters 组成)
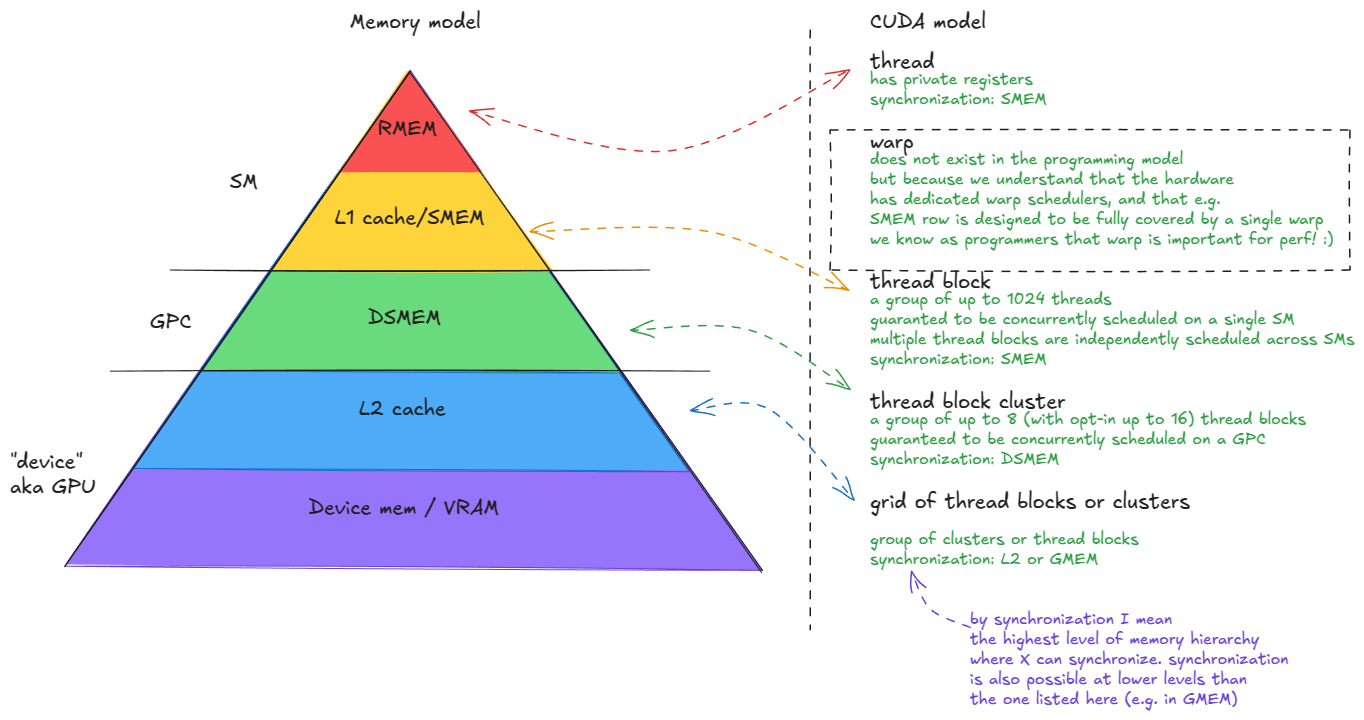
Figure 5: CUDA Programming Model: threads, warps, blocks, clusters, grids
每个线程都通过 gridDim、blockIdx、blockDim、threadIdx 等变量“感知”自己在 CUDA 层次结构中的位置。这些变量在内部存储于特殊寄存器中,并在 kernel 启动时由 CUDA runtime 初始化。
这种位置信息使得在 GPU 上划分工作变得非常简单。例如,如果我们要处理一张 1024×1024 的图像,可以将其划分为 32×32 的 thread block,每个 block 包含 32×32 个线程。
每个线程随后可以计算自己的全局坐标,例如:
1
2
const int x = blockIdx.x * blockDim.x + threadIdx.x
const int y = blockIdx.y * blockDim.y + threadIdx.y
然后使用这些坐标从 global memory(image[x][y])中读取属于自己的像素,执行某个逐点(pointwise)操作,并将结果写回。
这些变量之间的关系如下图所示:
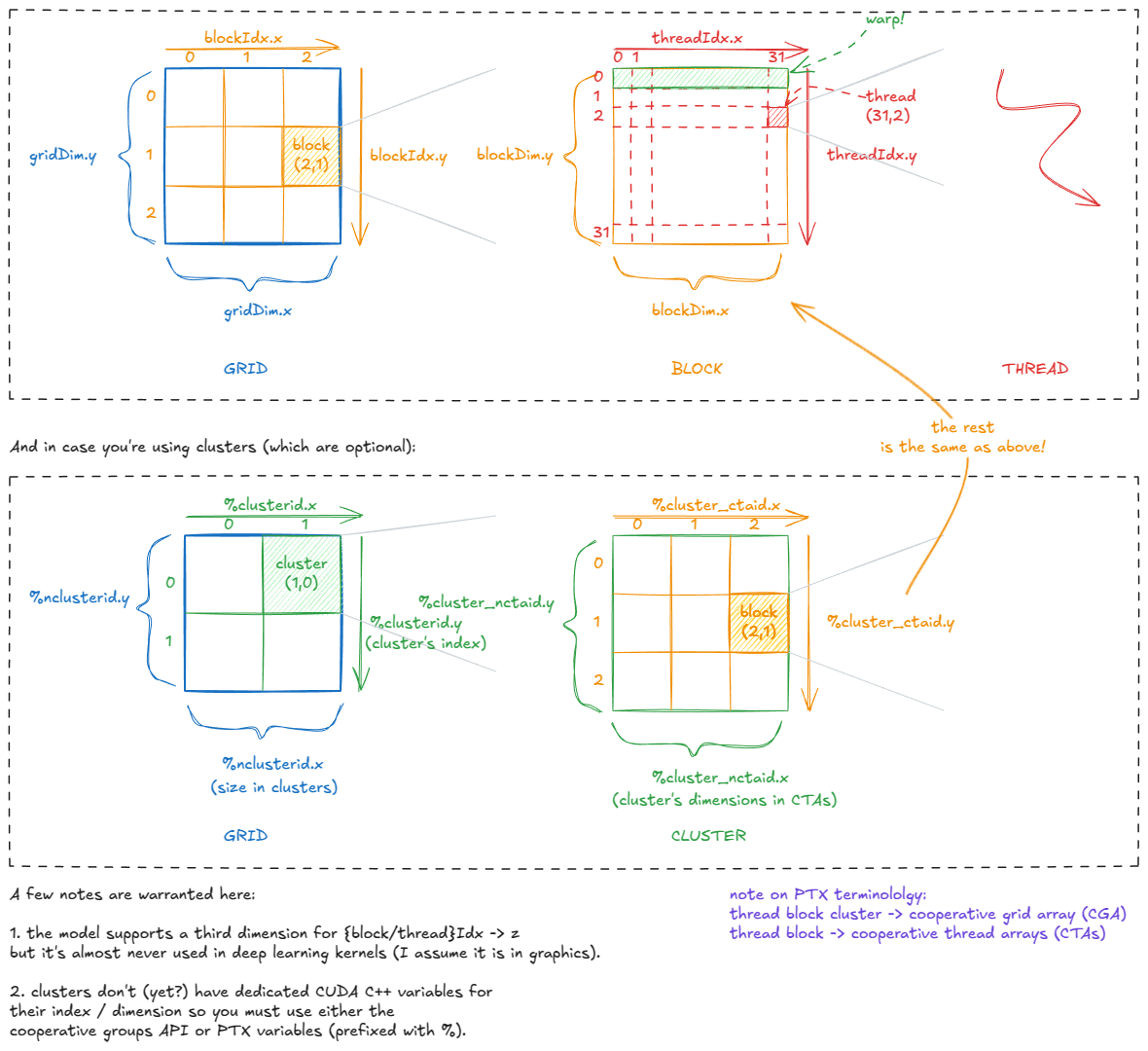
Figure 6: CUDA's built-in variables: how threads know where they are
如图所示,在实践中我们通常使用 1D 或 2D 的 grid/cluster/block 形状。不过在内部,它们始终可以根据需要进行逻辑重组。
例如,如果
threadIdx.x从 0–1023 变化(一个包含 1024 个线程的 1D block),我们可以将其拆分为x = threadIdx.x % 32与y = threadIdx.x / 32,从而在逻辑上将该 block 重塑为 32×32 的 2D 布局。
将 CUDA 模型与硬件对应起来,现在有一个事实应该非常清楚:一个 thread block 至少应包含 4 个 warp(即 128 个线程)。
为什么?
- 一个 thread block 常驻于单个 SM 上。
- 每个 SM 有 4 个 warp 调度器 —— 为了充分利用硬件资源,你不希望它们处于空闲状态。
📝关于 4 个 warp 的更多原因:
我们稍后会深入讨论,不过需要注意的是,在 Hopper 上 warp-group(4 个 warp)是执行 WGMMA(matmul)Tensor Core 指令的基本单位。
此外,在 persistent kernel 中,我们通常每个 SM 只启动一个 thread block,因此必须合理组织工作,以确保所有 warp 调度器都保持忙碌。
掌握了 CUDA 编程模型的术语之后,我们可以继续深入 GPU 的架构。
GMEM 模型
让我们深入 GMEM。如前所述,它由多层 DRAM 堆叠而成,底部配有逻辑层(HBM)。那么 DRAM 究竟是什么?

Figure 7: Inside a DRAM cell: transistor + capacitor, wordline + bitline
现在我们已经理解了单个 bit 是如何存储的,让我们将视角扩展到整个内存矩阵。从高层来看,其结构如下:
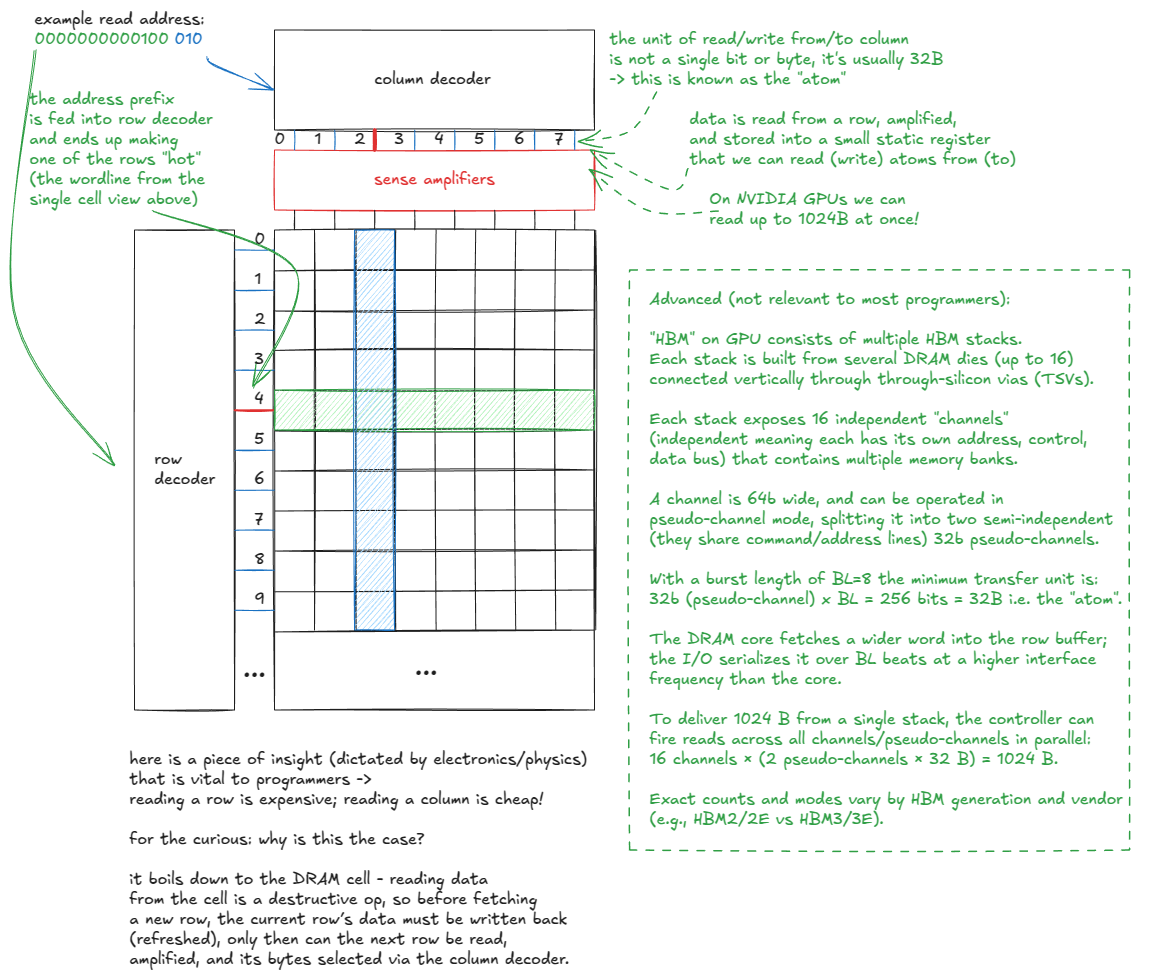
Figure 8: GMEM model
📝关于 HBM 的进一步阅读:
如果你想更深入了解 HBM,我推荐论文《Demystifying the Characteristics of High Bandwidth Memory for Real-Time Systems》 [21]。
因此我们可以得出结论:由于 DRAM 单元的物理特性,访问模式至关重要。如下所示:
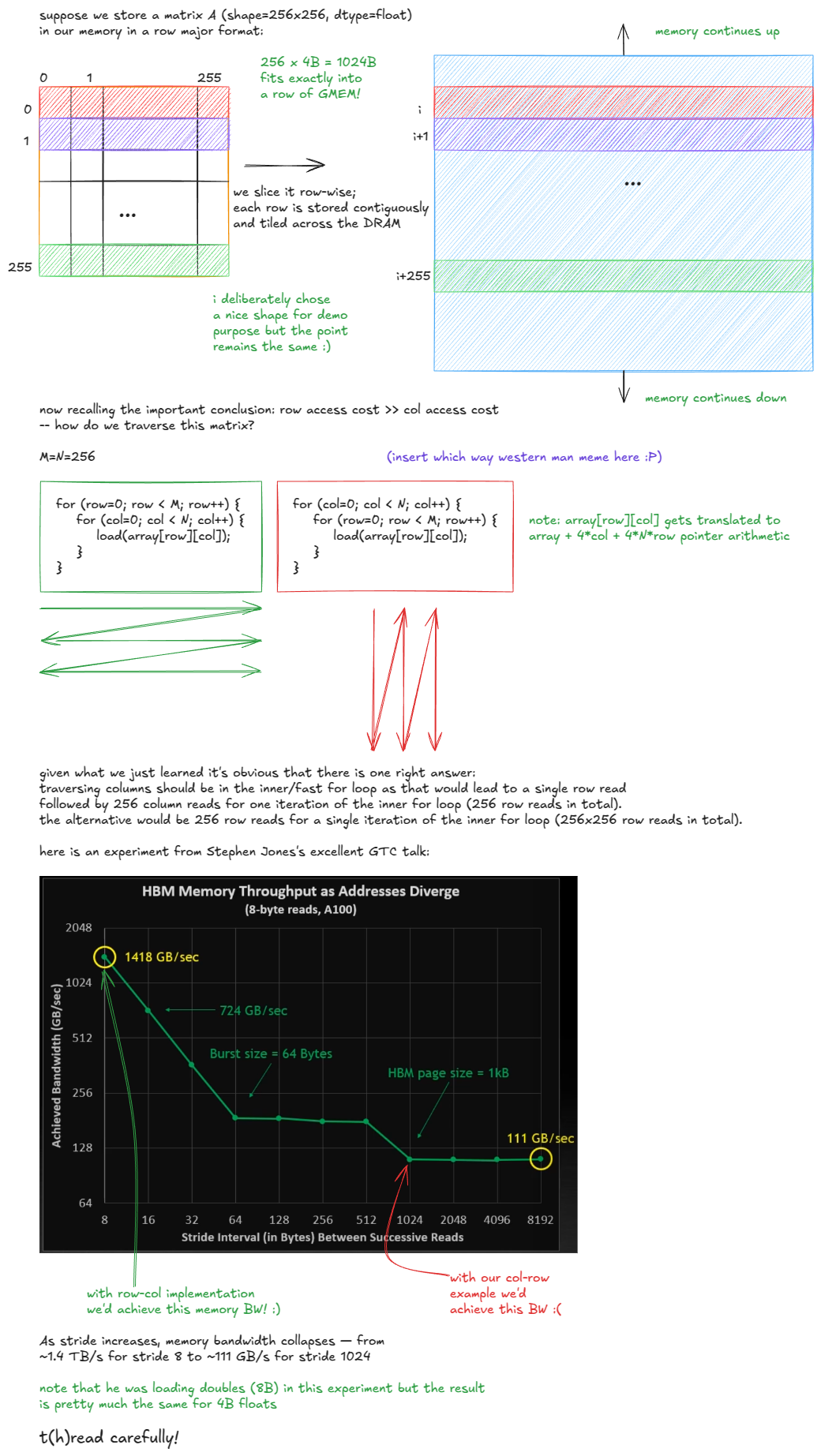
Figure 9: Effect of access pattern in GMEM
Stephen Jones 的演讲《How CUDA Programming Works》 [4]也非常值得观看。
如果我们示例中的矩阵是 column-major 存储,那么情况将完全相反:一列中的元素将连续存储,因此为了避免 DRAM 访问惩罚,应在内层循环中遍历行。
所以当人们说“GMEM coalescing 非常重要”时,意思正是:线程应访问连续的内存地址,以尽量减少触及的 DRAM 行数。
接下来,让我们看看 SMEM 的工作机制。
SMEM 模型
Shared memory(SMEM)与 GMEM 具有截然不同的性质。它由 SRAM 单元构成,而非 DRAM,这使其在速度与容量的权衡上呈现出本质差异。
SRAM 单元的具体设计细节并不重要 —— 只需知道存储一个 bit 需要更多晶体管即可。你可以自行搜索 “SRAM cell”。
SMEM 被组织为 32 个 bank,每个 bank 宽 32 bit(4 字节):
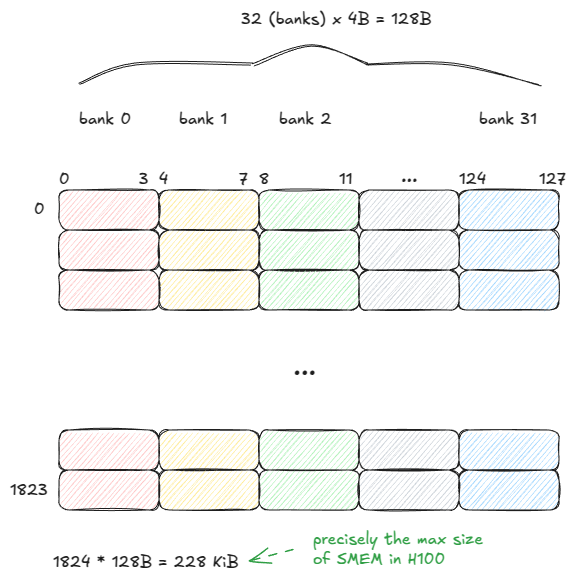
Figure 10: SMEM model
SMEM 可以在一个 cycle 内同时从全部 32 个 bank 提供数据(共 128B)—— 但前提是满足一个规则:
同一个 warp 内的线程不能访问同一 bank 中的不同地址,否则请求会被串行化到多个 cycle 中。
这种情况被称为 bank conflict。如果 N 个线程访问同一 bank 的不同地址,就会产生 N 路 bank conflict,该 warp 的内存请求需要 N 个 cycle 才能完成。
在最坏情况下,32 个线程分别访问同一 bank 中的不同地址,吞吐率将下降 32 倍。
举例来说,假设 warp 大小为 5,下图中的两种访问模式分别需要 3 个 cycle 与 1 个 cycle:
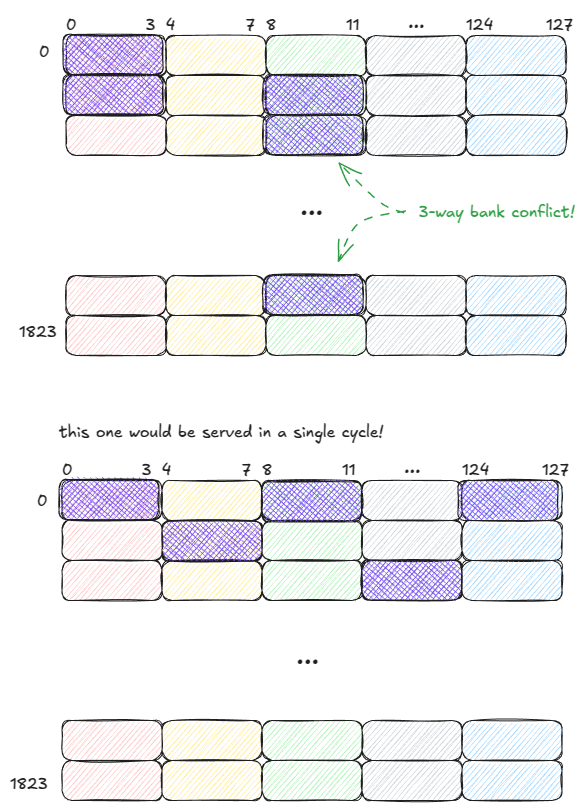
Figure 11: SMEM: good vs. bad access patterns
需要强调的是:如果一个 warp 内多个线程访问同一 bank 中的同一地址,SMEM 可以将该值广播(broadcast)或多播(multicast)给所有线程。
在下图示例中,请求在一个 cycle 内完成:
- Bank 1 可将一个值多播给 2 个线程
- Bank 2 可将一个值多播给 3 个线程
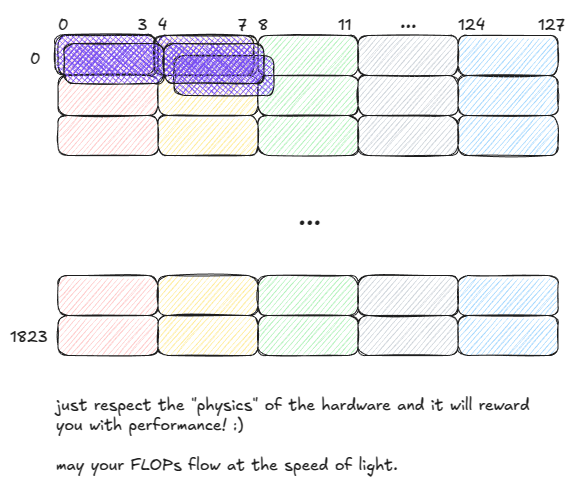
Figure 12: SMEM: multicasting (served in a single cycle)
现在,我们来到硬件拼图的最后一块:L1 cache。
L1 模型
我们已经看到 L1 与 SMEM 共享相同的物理存储空间,但 L1 在此之上增加了一层由硬件管理的结构与逻辑。
从高层来看,L1 cache 的逻辑流程如下:
- 一个 warp 发出内存请求(访问 SMEM 或 GMEM)。
- 请求进入 MIO pipeline,并被分发至 LSUIN 路由器。
- 路由器对请求进行分流:SMEM 访问直接从 data array 中提供,而 GMEM 访问进入 tag 比较阶段。
- 在 tag 阶段,GMEM 地址的 tag 会与目标 set 中存储的 tag 进行比较,以判断数据是否驻留在 L1 中。
- 若发生 hit,请求直接从 data array 提供(类似 SMEM)。
- 若发生 miss,请求会继续传递到 L2(以及必要时更远的 GMEM 或对端 GPU 内存)。当数据返回时,会被缓存到 L1 中,替换现有 cache line,并同时返回给发出请求的 warp。
如下图所示:
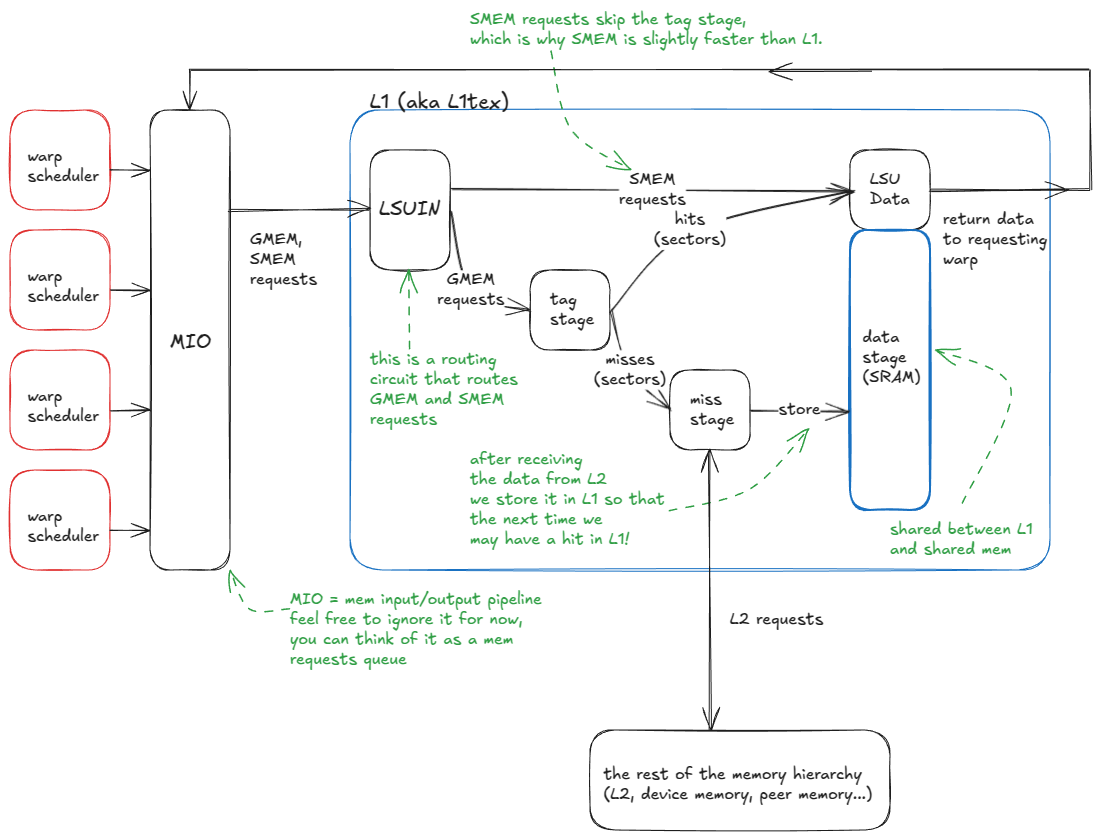
Figure 13: L1 cache model
让我们进一步深入,分别观察 tag 阶段与 data 阶段的结构:
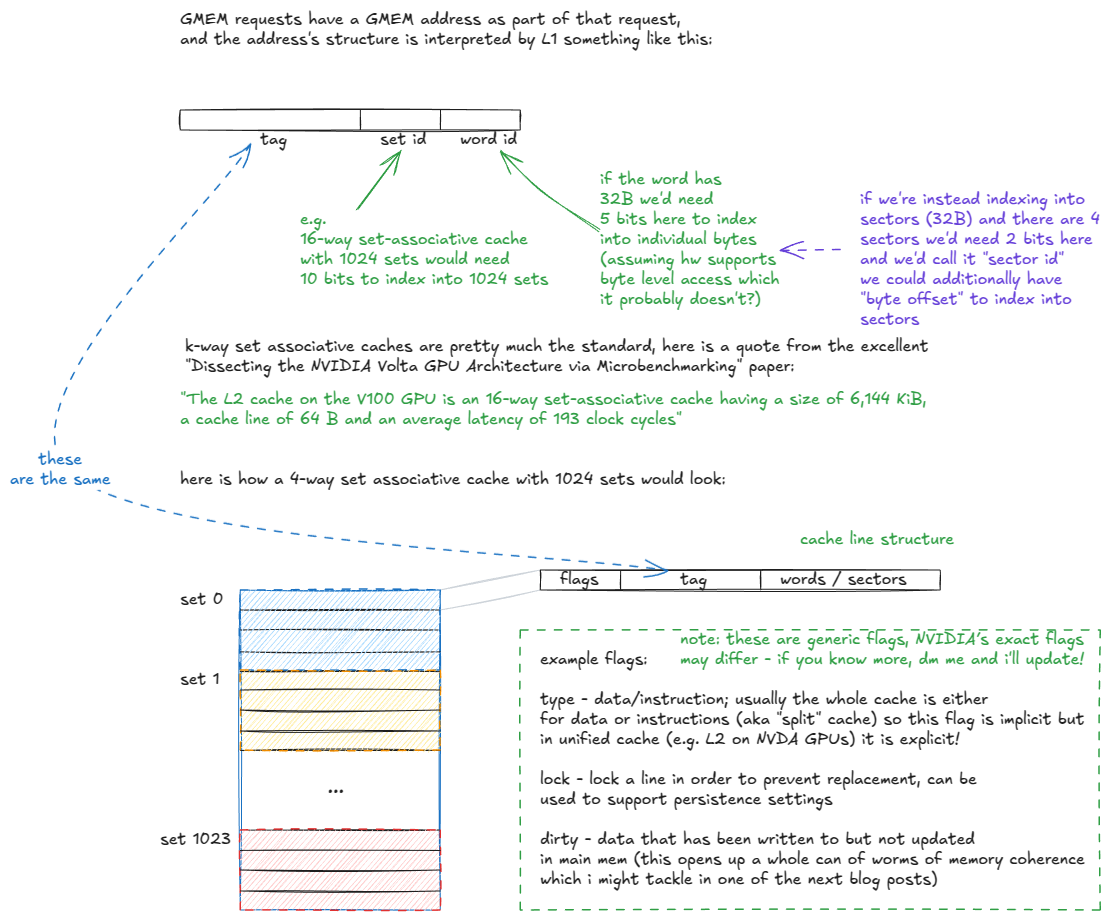
Figure 14: Breakdown of k-way set-associative cache organization
当一个 GMEM 地址进入 tag 阶段时,命中/未命中逻辑如下展开:
- tag 阶段接收 GMEM 地址。
- 提取 set id 位,并检查该 set 中的所有 cache line(tag)。
- 若找到 tag 匹配(潜在 cache hit):
- 检查该 cache line 的有效位。
- 若无效 → 视为 cache miss(进入步骤 4)。
- 若有效 → 从 data array 中取出所需 sector,并传递到 warp 的寄存器。
- 检查该 cache line 的有效位。
- 若未找到匹配(cache miss),请求会被路由至更高层内存层次(L2 及以上)。
- 当数据从 L2 返回后,会根据替换策略(例如 pseudo-LRU)存储到对应 set 中,同时返回给发出请求的 warp。
需要注意的是,L2 与 L1 在结构上并无本质差异,只是它是全局的(而非 per-SM)、容量更大(关联度更高)、被划分为两个通过 crossbar 连接的 slice,并支持更复杂的持久化与缓存策略。
至此,我们已经覆盖了理解后续内容所需的关键 GPU 硬件组件。
GPU 汇编语言:PTX 与 SASS
现在,让我们从硬件层面上升一层,来到 ISA(Instruction Set Architecture,指令集架构)。ISA 是处理器(例如 NVIDIA GPU)可以执行的全部指令集合,包括它们的二进制编码(opcode、operand 等)以及行为语义。它定义了程序员如何指挥硬件完成有用的工作。
ISA 的人类可读形式称为 assembly(汇编):程序员无需编写诸如 0x1fff…3B 这样的原始二进制,而是使用类似 FMA R12, R13, R14, R15 这样的助记符来表达同一条指令。
在 NVIDIA GPU 上,原生 ISA 被称为 SASS。不幸的是,它的官方文档相对匮乏 —— 尤其是针对最新一代 GPU。较早的架构有部分或全部被逆向工程解析,但官方资料依然有限。相关文档可在官方 CUDA binary utilities 文档 [6]中查阅。
PTX 是 NVIDIA 的 虚拟 ISA:面向抽象 GPU 的指令集。PTX 代码不会被直接执行,而是由 ptxas 编译为原生 ISA(SASS)。
PTX 的关键优势在于前向兼容性。十年前编译为 PTX 的 CUDA 程序,今天依然可以在诸如 Blackwell 这样的现代 GPU 上运行。它或许不能充分利用最新硬件特性,但能够正确执行。
之所以能够实现这一点,是因为 PTX 会与原生 SASS 一同嵌入 CUDA binary 中。当该 binary 在未来架构的 GPU 上运行时,如果没有匹配的 SASS 代码,就会将 PTX JIT 编译为目标架构的 SASS:
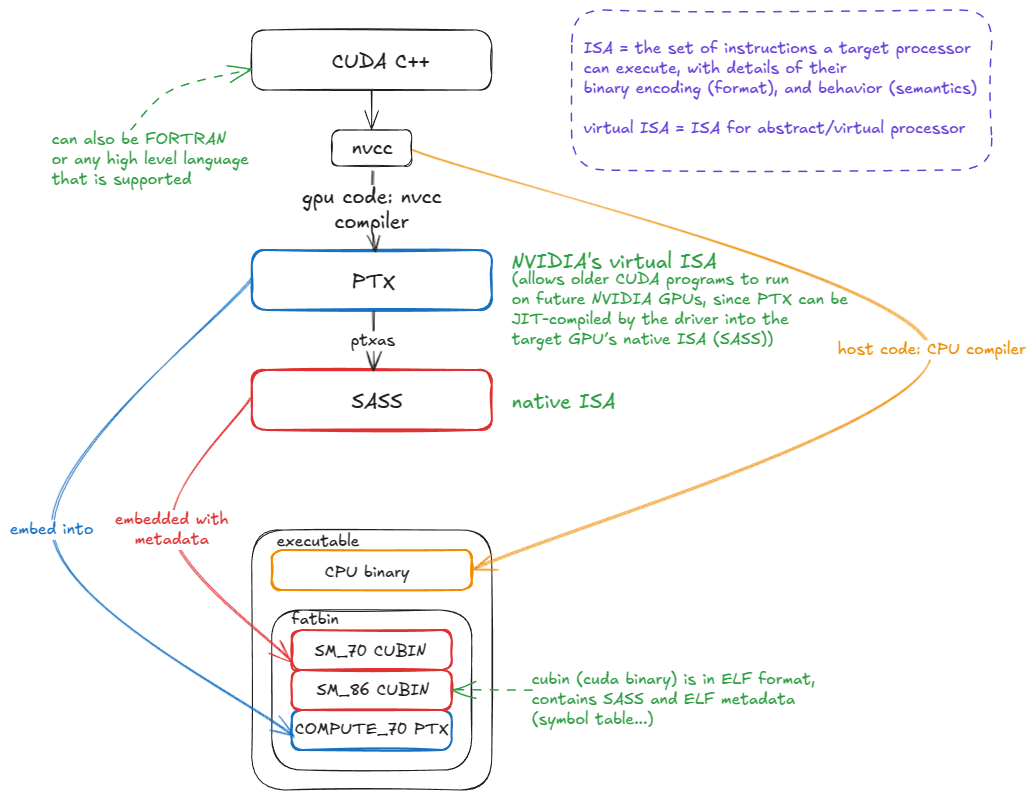
Figure 15: CUDA compilation flow: from CUDA C++ → PTX → SASS
为什么要关心 PTX / SASS?
因为最后那几个百分点的性能,往往就藏在这里。
在今天这个规模下,“几个百分点”绝对不是小数目:如果你在 30,000 张 NVIDIA H100 上训练一个 LLM,仅仅把某个核心 kernel 的性能提升 1%,就可能意味着节省数百万美元的成本。
正如我的朋友 Aroun 常说的那样:在大规模训练 / 推理场景下,我们关心的是 O(NR),而不是 O(N)。(这里 NR = nuclear reactors,核反应堆。) 换句话说,新的渐进复杂度类别几乎不可能再被发现了 —— 那些“数量级飞跃”的优化机会基本已经被榨干。如今真正的收益,来自于在成千上万张 GPU 上压榨出 ~1% 的效率提升 —— 这相当于省下几座 SMR(小型模块化核反应堆)的能耗。
如果你想更深入了解 SASS,我强烈推荐 Aroun 的视频课程《Introduction to SASS & GPU Microarchitecture》 [7]。
理解 SASS 的意义,并不是说你以后要直接用 SASS 写 CUDA kernel。真正的意义在于:
当你写 CUDA C++ 时,要始终对编译器生成的 PTX / SASS 保持“贴身跟踪”。
这样你才能确认:
- 你给出的优化提示(例如
#pragma unroll、向量化 load 等) - 是否真的被编译器降级为你期望的底层指令(例如
LDG.128)
一个非常经典的例子来自 Citadel 论文:
“Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking”
作者通过手动修改 SASS,避免了 memory bank conflict,使性能从 132 GFLOP/s 提升到 152 GFLOP/s —— 提升幅度达到 15.4%。
另外还要注意:
有些指令在 CUDA C++ 中根本没有对应语法,你只能通过 inline PTX 来使用它们。我们将在第 4 章看到例子。
既然现在(希望)你已经被说服 PTX / SASS 很重要,我们从一个最简单的 matmul kernel开始,作为本章后续分析的贯穿示例。随后我们会对它的汇编进行深入剖析。
让我们从最简单的情况开始:一个面向“串行处理器”(例如 CPU)的朴素矩阵乘法 kernel:
1
2
3
4
5
6
7
8
9
for (int m = 0; m < M; m++) {
for (int n = 0; n < N; n++) {
float tmp = 0.0f; // accumulator for dot product
for (int k = 0; k < K; k++) {
tmp += A[m][k] * B[k][n]; // A and B are input matrices
}
C[m][n] = tmp; // C is the output matrix
}
}
我们遍历输出矩阵 C 的每一行(m)和每一列(n),在每个位置计算一个点积(C[m,n] = dot(a[m,k], b[k,n]))。这就是教科书中对矩阵乘法的定义:
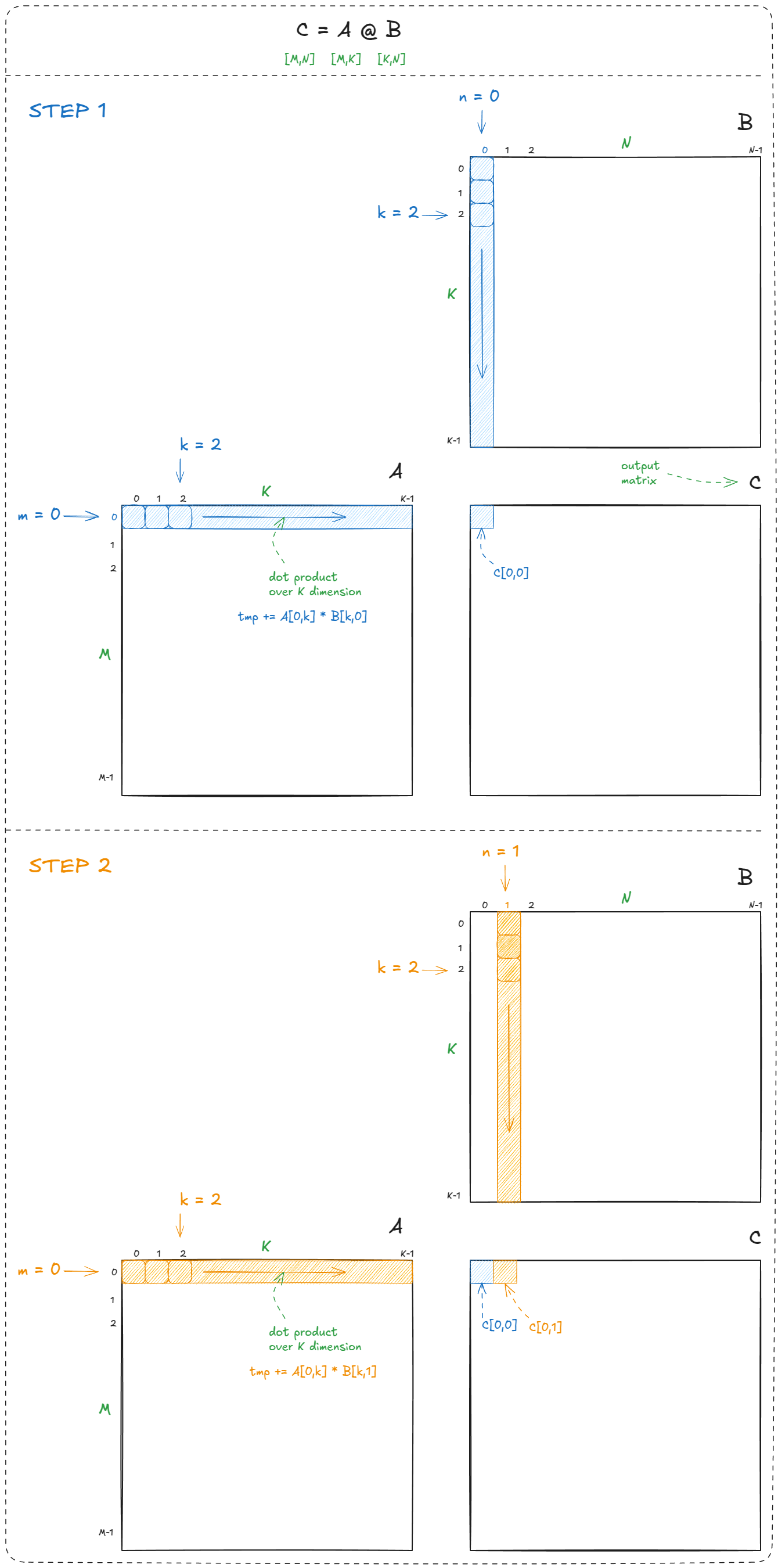
Figure 16: Naive CPU matmul example
总体来看,矩阵乘法需要计算 M × N 个点积。每个点积包含 K 次乘加操作,因此总的计算量为 2 × M × N × K FLOPs(之所以乘以 2,是因为按照惯例,我们将一次 FMA 视为一次乘法加一次加法)。
并行性在哪里?
所有这些点积彼此独立。计算 C[0,1] 并不需要等待 C[0,0] 完成。这种独立性意味着我们可以在两个最外层循环(m 和 n)上进行并行化。
有了这个认识,我们来看一个最简单的 GPU kernel。我们采用一个稍微更通用的形式:C = alpha * A @ B + beta * C。这就是经典的 GEMM(General Matrix Multiply)。当设置 alpha = 1.0 且 beta = 0.0 时,就退化为更简单的 C = A @ B。
Kernel 代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// __global__ keyword declares a GPU kernel
__global__ void naive_kernel(int M, int N, int K, float alpha,
const float *A, const float *B,
float beta, float *C) {
int BLOCKSIZE=32;
const int row = blockIdx.x * BLOCKSIZE + (threadIdx.x / BLOCKSIZE);
const int col = blockIdx.y * BLOCKSIZE + (threadIdx.x % BLOCKSIZE);
if (row < M && col < N) { // guard in case some threads are outside the range
float tmp = 0.0;
// compute dot product
for (int i = 0; i < K; ++i) {
tmp += A[row * K + i] * B[i * N + col];
}
// GEMM: C = alpha * A @ B + beta * C
C[row * N + col] = alpha * tmp + beta * C[row * N + col];
}
}
我们像这样启动它:
1
2
3
4
5
6
7
// create as many blocks as necessary to map all of C
dim3 gridDim(CEIL_DIV(M, 32), CEIL_DIV(N, 32), 1);
// 32 * 32 = 1024 thread per block
dim3 blockDim(32 * 32);
// launch the asynchronous execution of the kernel on the device
// the function call returns immediately on the host
naive_kernel<<<gridDim, blockDim>>>(M, N, K, alpha, A, B, beta, C);
在这里你可以观察到几件事情:
- Kernel 是从单个线程的视角编写的。这遵循 SIMT(Single Instruction, Multiple Threads)模型:程序员只需要描述一个线程的工作内容,而 CUDA 负责 grid、cluster 和 block 的启动与初始化。(其他编程模型,例如 OpenAI 的 Triton [22],则允许你从一个 tile 的视角来编写代码。)
- 每个线程利用自己的 block 索引和 thread 索引(我们之前讨论过的变量)来计算在
C中对应的 (row,col) 坐标,并写出相应的点积结果。 - 我们使用尽可能多的 32×32 线程块(每块 1024 个线程)对输出矩阵进行分块。
- 如果
M或N不能被 32 整除,就会有一些线程落在C的有效输出区域之外,这也是为什么代码中需要加上 guard 判断。
最后两点结合在一起,会产生一个通常被称为 tile quantization 的现象:
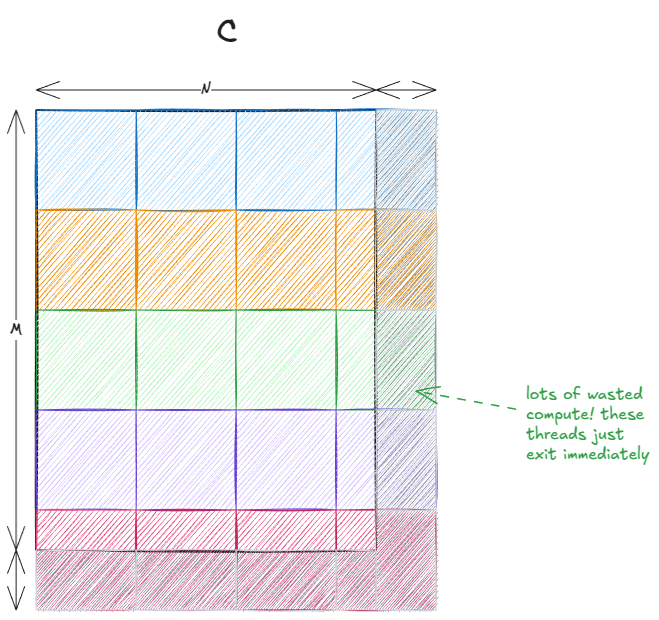
Figure 17: Tile quantization
当 tile 的尺寸相对于输出矩阵较大时,这种现象会更加明显。在我们的例子中不存在这个问题,因为 32 可以整除 4096。但如果矩阵尺寸是 33×33,那么大约 75% 的线程最终都会处于空转状态,没有做任何有用的计算。
其实,这段代码也可以写得更简单一些:我们可以传入一个 2D block,而不是 1D block。这样就不需要把 block size 固定写死为 32,可以直接使用
threadIdx.x和threadIdx.y。在内部实现上,1D 结构本质上也是通过索引运算转换成 2D 的:threadIdx.x / BLOCKSIZE和threadIdx.x % BLOCKSIZE。因此在实践中,两种写法并不会带来本质差异。
这段代码最初是我从 Simon’s blog [9] 改编而来,接下来我会对它进行深入的 PTX/SASS 分析(马上就到)。正因为如此,我不希望改动代码结构——哪怕是很小的改动,也可能生成不同的 PTX/SASS,从而影响后续分析。
接下来我们更仔细地看看这个 kernel 实际上在做什么。本文后续内容默认 M = N = 4096。本例中所有矩阵均采用 row-major 存储格式(在后面的某些示例中,B 会改为 column-major——这是常见的约定)。
线程的逻辑组织方式如下所示:
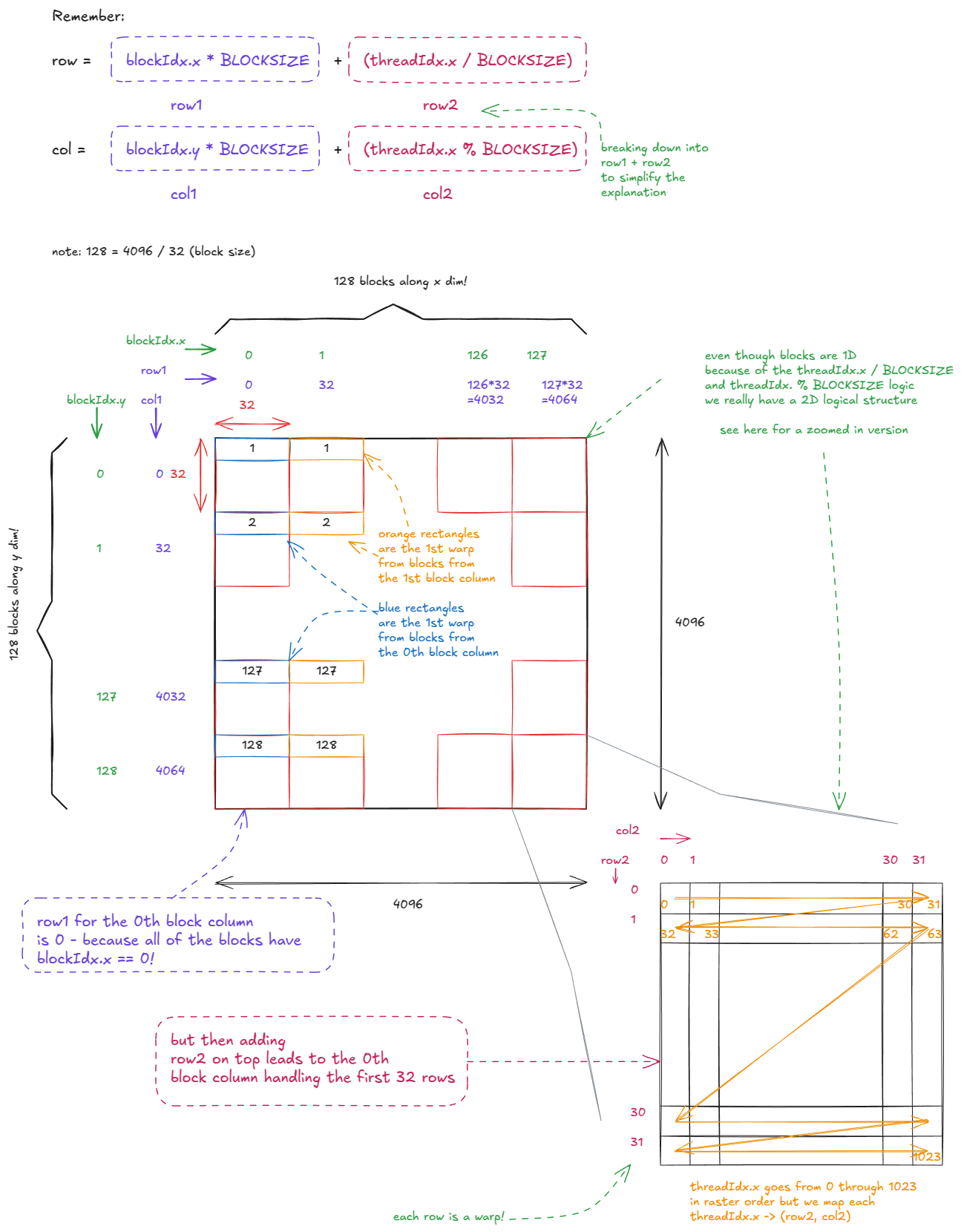
Figure 18: Thread organization in naive matmul kernel
而 matmul 的计算逻辑本身如下图所示:

Figure 19: Naive matmul kernel
当我们对 GMEM 的访问是合并访问(coalesced)时,硬件会自动进行一些非常有趣的优化:
- (矩阵 A)当一个 warp 从
A读取数据时,32 条逐线程发出的LDG.32指令(全部来自同一个地址)会被合并为一条 warp 级别的LDG.32指令,其结果会广播给 warp 内的所有线程。 - (矩阵 B)当一个 warp 从
B读取数据时,32 条连续地址的逐线程LDG.32指令会被合并为一次 128B 的 warp 级加载。这依赖于线程沿着连续维度读取数据。如果线程是沿列方向(非连续方向)读取,那么硬件就必须发出多条 warp 级加载指令。
注意,我们一共启动了 (4096/32) * (4096/32) = 16,384 个 thread block。然而,我使用的 H100 PCIe 只有 114 个 SM。
这就引出了一个问题:每个 SM 上最多能同时运行多少个 block?
一般来说,有三种资源会限制并发度:
- 寄存器(Registers)
- 共享内存(SMEM)
- 线程 / warp 数量
通过 Nsight Compute profiler(ncu --set full -o out.ncu-rep naive_kernel,见下图)我们可以看到,这个 kernel 每个线程使用 32 个寄存器。每个 block 有 1024 个线程,因此每个 block 需要 1024×32 = 32,768 个寄存器。每个 SM 拥有 65,536 个寄存器(这些常量可以在 CUDA C programming guide [10] 中查到),因此最多只能在每个 SM 上驻留 2 个 block。
📝Note:
小提示:在编译时可以传入
--ptxas-options=-v,让编译器输出寄存器使用情况以及其他资源占用信息。nvdisasm也是一个很有帮助的小工具。
在 Hopper 架构(compute capability 9.0)上,每个 SM 最多支持 2048 个线程。每个 block 有 1024 个线程,因此这一限制同样将我们限制为每个 SM 最多 2 个 block。
还记得在硬件章节中提到的,即便 kernel 没有显式使用 SMEM,每个 block 仍然会有 1024B 的系统级开销。如果每个 SM 使用默认的 8192B SMEM 配置(没有把上限调到 228 KiB),理论上最多可以支持 8 个 block。
综合以上限制:max blocks/SM = min(2,2,8) = 2。
因此,在任意时刻,这个 kernel 在整个 GPU 上最多可以同时驻留 114×2 = 228 个 thread block。
这意味着我们需要 16,384 / 228 ≈ 71.86 个所谓的 waves 才能完成整个 matmul 运算。
📝Occupancy
在 CUDA 术语中,occupancy 通常指的是一个 SM 上可以同时运行的 block 数量。此外还有一个密切相关的定义:
Occupancy(以 warp 为单位):活跃 warp 数量与每个 SM 上最大 warp 数量的比值。
这里的“活跃 warp”指的是在 kernel 启动时,已经分配好资源(寄存器、SMEM 等)的线程块所包含的 warp。

Figure 20: Nsight Compute: Occupancy, Waves info
这里还值得一提的是:就像 tile quantization 一样,也存在一个叫做 wave quantization 的概念。当 wave 的数量较少时,这种现象尤其明显。
例如,假设我启动了一个包含 114 个 block 的 kernel(正好等于我这块 H100 PCIe 上的 SM 数量),并且假设每个 SM 同时只能运行 1 个 block。这样一来,每个 SM 上只有一个 block,整个 kernel 会在一个 wave 内完成。现在如果我把 block 数量增加到 115 个,执行时间几乎会翻倍——因为我们需要两个 wave——但在第二个 wave 中,大部分资源其实是空闲的,因为只有一个 block 在运行:
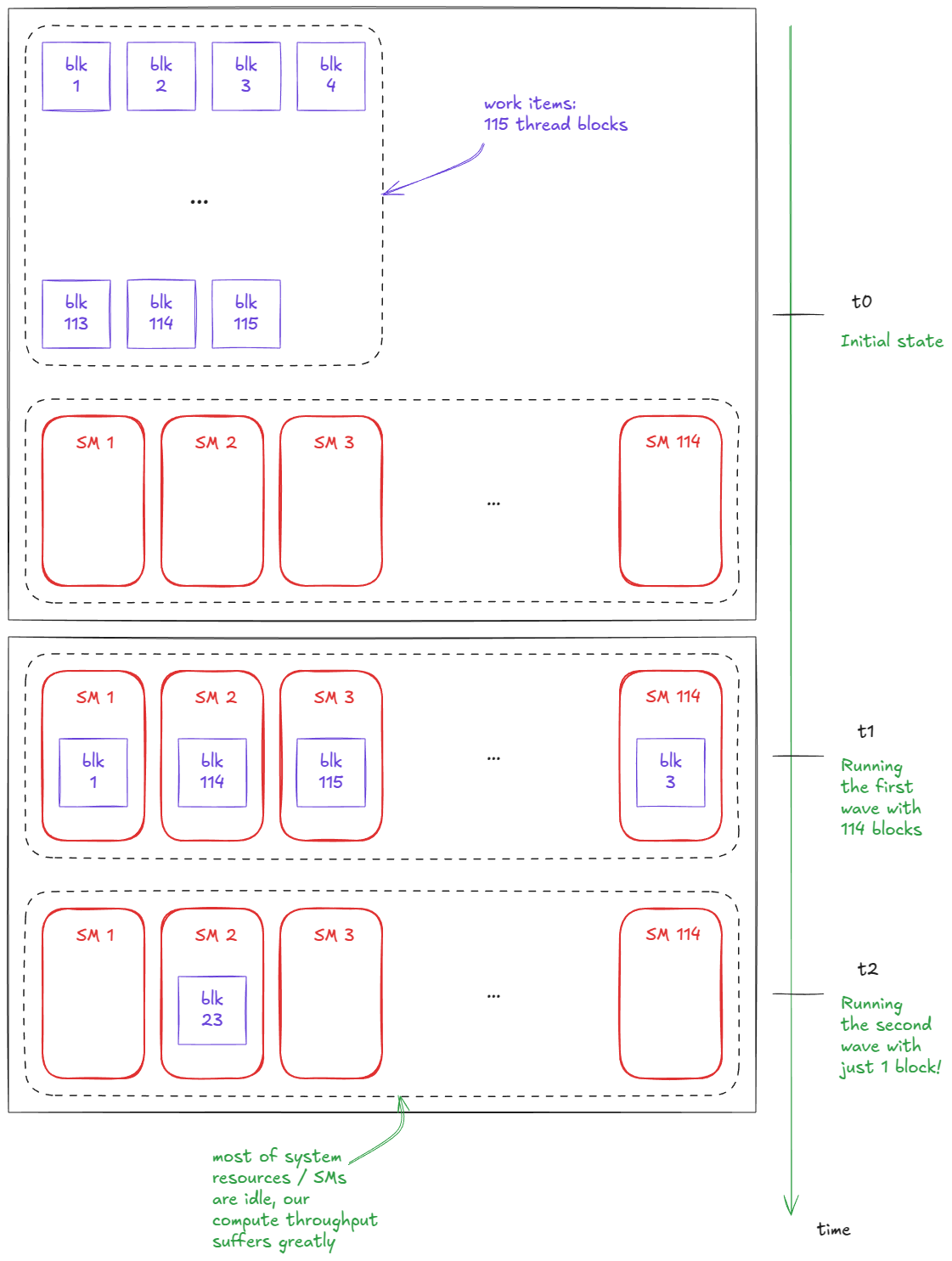
Figure 21: Wave quantization
在完成了对 naive matmul kernel 的基础分析之后,我们现在把视角切换到 PTX/SASS。以下是我使用的编译设置(Godbolt):
1
2
3
4
5
6
7
8
9
compilation settings:
nvcc 12.5.1
-O3 # 最激进的、符合标准的优化级别,会启用循环展开等优化
-DNDEBUG # 将 assert() 变为 noop,对于我们这个简单 kernel 没有影响
--generate-code=arch=compute_90,code=[compute_90,sm_90a] # 为 H100 嵌入 PTX/SASS
--ptxas-options=-v # 让 ptxas 在编译期间打印每个 kernel 的资源使用情况
-std=c++17 # 按 ISO C++17 标准编译,对本例影响不大
# --fast-math # 未启用,对本 kernel 影响较小
还有一个重要的编译选项是
--use_fast_math。它通过牺牲数值精度来换取更高的性能,主要影响 fp32 运算。例如,它会将标准数学函数替换为更快的近似内建函数(如sinf->__sinf),启用对非规格化数(denormals,即绝对值小于最小“正常”可表示浮点数的极小数)的 flush-to-zero(ftz)模式等等。
下面是前面给出的 CUDA C++ kernel 对应的 PTX 代码,并附有注释。我是手动对其进行解读的,以便更深入理解指令集架构。你可以放大图片,花点时间仔细观察其结构(或者直接跳到图片后阅读我的总结,再回来看图也可以):

Figure 22: PTX code corresponding to naive matmul CUDA kernel
总结来说,PTX 代码的大致流程如下:
- 计算
row和col变量。有趣的是,编译器在计算col时使用了bfi(bit field insert)指令,而不是简单地对寄存器r2和r3做加法。这可能是为了在执行流水线之间进行负载均衡,把工作分配给利用率较低的执行单元——但需要注意的是,bfi本身并不天然比加法更快。 - 如果当前线程超出
C的合法范围,则提前退出(guard 逻辑)。 - 如果
K < 1,则直接跳转到对C的写回阶段(此时tmp为 0.0)。 - 如果
K <= 3,则跳转到尾循环(tail loop)。 - 否则,如果
K > 3:在进入主循环之前,先计算A和B的基地址偏移。 - 主循环(展开 ×4)。每次迭代执行 4 次 FMA 操作,并与加载指令和地址计算交错执行。
- 尾循环(
<= 3次迭代)。对剩余的点积步骤进行计算,但不做展开。 - 收尾阶段(epilogue):加载
C的原始值,执行 GEMM 更新(alpha * A @ B + beta * C),然后通过st.global.f32将结果写回全局内存。
从中可以看到编译器做了几项优化:提前退出、循环展开、主循环与尾循环拆分,以及看起来类似于流水线负载均衡的处理(如果我关于 bfi 的推测是正确的话)。
尤其是循环展开这一点非常重要,因为它暴露了指令级并行性(ILP)。warp 不需要那么快就被切换出去执行其他 warp,因为它自身就还有独立指令可以发射——这正是隐藏延迟的关键所在。
什么是 ILP(Instruction-Level Parallelism)?
Instruction-Level Parallelism(ILP,指令级并行性)是指单个 warp 通过连续发射彼此独立的指令,使多条指令同时“在飞行中”的能力。较高的 ILP 使 warp 调度器能够在每个周期都发射一条新指令,而此前发射的指令仍在等待其执行延迟完成。
来看下面两段指令流(假设一次 FMA 需要 4 个周期):
1 )低 ILP(完全依赖链)
每一条 FMA 都依赖前一条的结果 => 无法并行调度 => 总延迟为 12(3×4)个周期。
2 )高 ILP(彼此独立的操作)
三条相互独立的 FMA => 调度器可以在连续的周期中发射它们。分别在周期 0、1、2 发射,结果在 4、5、6 周期就绪 => 总延迟为 6 个周期。
这就是为什么循环展开 / ILP 如此重要。
在调试时,你可能希望禁用循环展开,以便更容易分析 PTX/SASS。只需添加:
#pragma unroll 1。
循环展开还会减少分支(bra)指令的数量,使程序更加紧凑、高效。
我也观察到一些编译器的低效之处,例如:
- 不必要地将变量初始化为 0。
- 对
A地址的计算过于复杂。 - 存在一个多余的部分偏移量计算,本可以用一条指令完成,却拆成了两条。
很有意思!现在我们来看对应的 SASS 代码:

Figure 23: SASS code corresponding to naive matmul CUDA kernel
我只强调一下相较于 PTX 的差异:
- 循环现在被展开了 ×16!
- LDG 指令被移动到循环顶部,使计算与数据加载重叠。FMA 基本集中在每个展开块的后半部分。
- 存在 2 个尾循环:一个展开 8×,一个展开 4×,最后一个循环覆盖剩余的 3 次迭代。
我在 SASS 中也发现了一些有趣的编译器怪癖和低效之处:
- 程序计数器(
R1寄存器)被加载,但从未使用。不清楚原因? - 冗余的零初始化依然存在。
- 有一个谓词实际上是 noop:它总为真,因此跳转到标签
L_x_2(4× 展开循环)的分支永远不会被执行。 - 4× 展开循环中包含一条多余的
BRA指令——它最多只会执行一次。 - 在最后的
EXIT之后,代码落入一个无限 while 循环。这是实现细节上的副产物,还是一个小 bug? - 最后(这不是 bug),代码使用
NOP进行填充,以满足内存对齐要求。
挺有意思!我们已经对编译器在幕后做了些什么有了一些直观感受。
现在,在掌握了这些背景知识之后,我们换个方向,深入研究一些 SOTA kernel。
📝 下一章节的补充阅读:
我强烈推荐 Simon 的优秀博客文章,blog post。这篇文章曾是我深入研究内核的最初灵感来源。在本章中,我将以他提供的 kernel 10 [12] 代码作为参考。虽然代码本身看起来是受 CUTLASS 启发的(例如参见 这里 [13] 和 这里 [14]),我首先分析的是 Simon 的版本——所以这里我也沿用他的实现。
设计接近 SOTA 的同步 matmul kernel
在本章中,我们将拆解一个在以下约束条件下接近 SOTA 的 fp32 kernel:
- 不使用 TMA
- 不使用异步内存指令
- 不使用 tensor core
- 仅使用 fp32(不使用 bf16)
换句话说,这是在 pre-Volta GPU 模型下的 SOTA 实现(在 Volta/Ampere 上也接近 SOTA):
- Volta 引入了 tensor core
- Ampere 引入了异步内存指令
- Hopper 引入了 TMA
我们将要研究的技术称为 warp-tiling。
在深入讲解之前,我们先对之前的 kernel 做一个很小的改动,然后看看会发生什么。具体来说,我们修改 row 和 col 变量的计算方式。
原始版本:
1
2
const int row = blockIdx.x * BLOCKSIZE + (threadIdx.x / BLOCKSIZE);
const int col = blockIdx.y * BLOCKSIZE + (threadIdx.x % BLOCKSIZE);
修改后的版本:
1
2
const int row = blockIdx.x * BLOCKSIZE + (threadIdx.x % BLOCKSIZE);
const int col = blockIdx.y * BLOCKSIZE + (threadIdx.x / BLOCKSIZE);
换句话说,我们只是交换了 % 和 / 这两个运算符。
与前一个示例相比,在逻辑结构上唯一的变化就是 row2 和 col2 的对调:
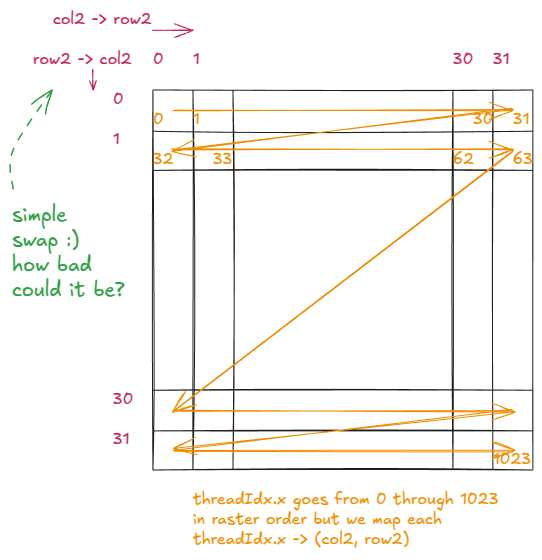
Figure 24: New logical organization of row2 and col2 variables
下面是修改后 kernel 的行为方式:
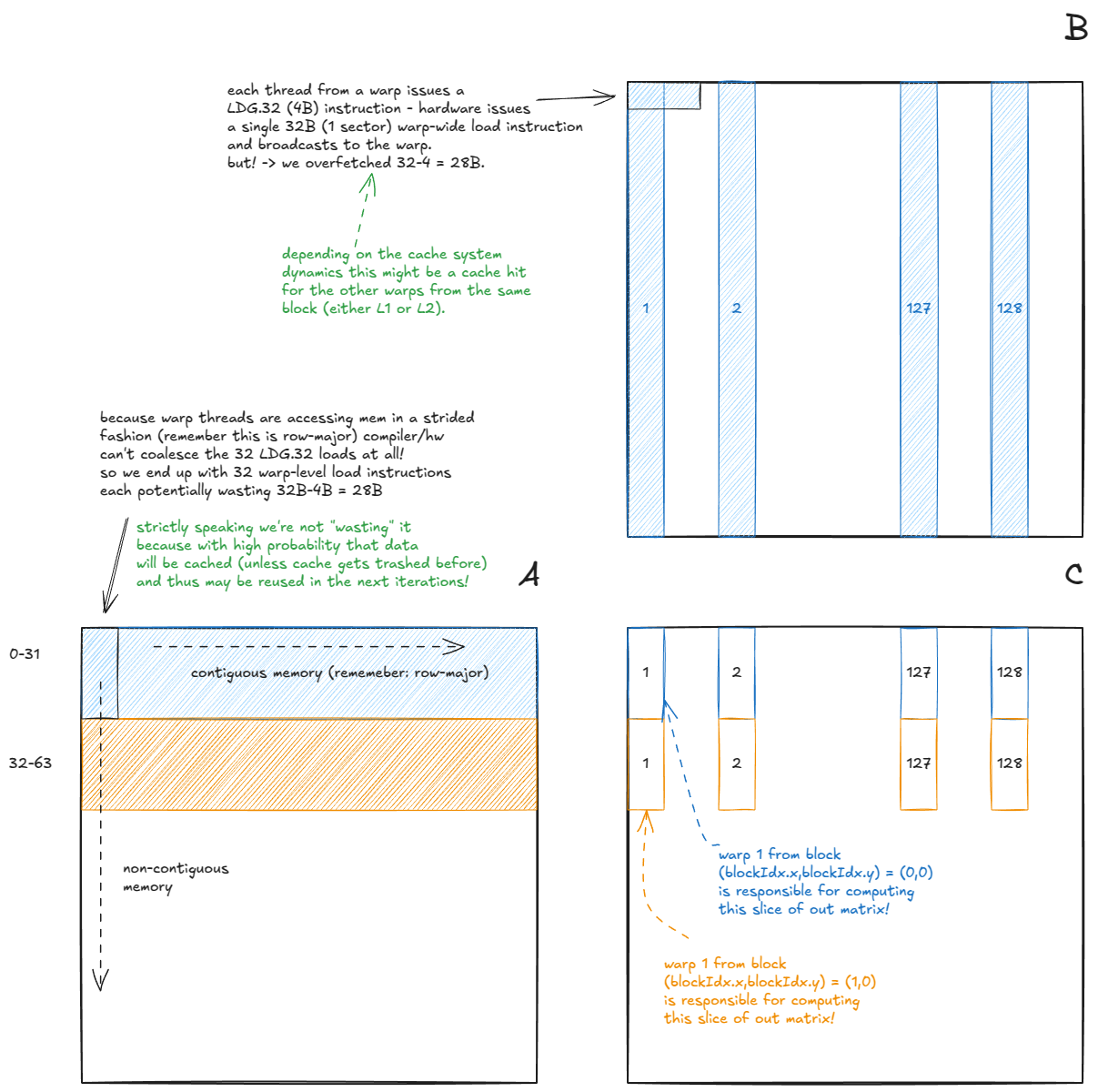
Figure 25: Naive kernel with uncoalesced GMEM access
这个看似无害的小改动,使我们的 GMEM 访问变成了非合并(uncoalesced)。
在我的 H100 PCIe 上,性能从 3171 GFLOP/s 直接跌到 243 GFLOP/s——整整慢了 13 倍。这正是我们在 GMEM 章节中看到的那种惩罚(Stephen Jones 的跨步 GMEM 访问实验)。
从表面上看,这不过是两个运算符的简单互换。但如果你脑中没有一套硬件执行模型,是根本无法预料会产生如此巨大的影响的。
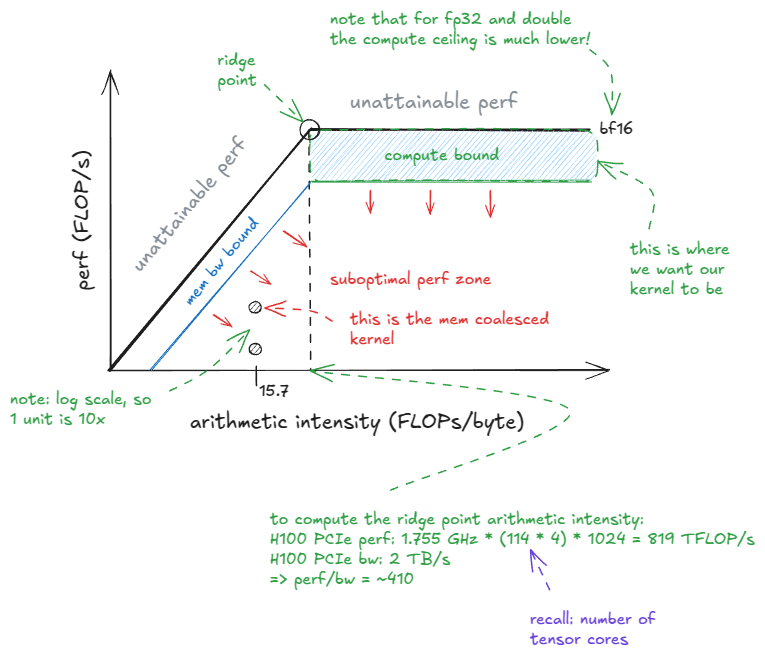
Figure 26: Roofline model
观察 roofline 模型可以发现,我们的 kernel 深深处于图中的 memory-bandwidth-bound 区域。既然我们为 NVIDIA 的计算能力付了高昂的费用,那当然应该努力把 kernel 推向 compute-bound 区域。
📝Roofline model
Roofline 模型在纵轴上绘制 性能(FLOP/s),横轴上绘制 算术强度(Arithmetic Intensity, AI)。
算术强度定义为:每从 device memory / GMEM 加载 1 字节数据所执行的 FLOP 数量(默认情况下)。
所谓的“ridge point”出现在:
峰值算力 / GMEM 带宽。对于我的 H100 PCIe,这个值大约是 ~410。只有当 AI 超过这个数值时,kernel 才能进入 compute-bound 区域。
在继续之前,我们再回顾一下顺序版本的 matmul 代码,作为参考:
1
2
3
4
5
6
7
8
9
for (int m = 0; m < M; m++) {
for (int n = 0; n < N; n++) {
float tmp = 0.0f; // 点积的累加器
for (int k = 0; k < K; k++) {
tmp += A[m][k] * B[k][n];
}
C[m][n] = tmp;
}
}
我想强调的关键点是,这段代码在语义上对循环顺序是不敏感的。也就是说,我们可以对这三重嵌套循环进行任意一种 3! = 6 种排列,最终结果仍然是正确的 matmul。
在这六种排列中,最有意思的是把 K 放在最外层循环。(至于 m 和 n 的相对顺序影响较小,我们假设采用“标准”的 m-n 顺序):
1
2
3
4
5
6
7
8
for (int k = 0; k < K; k++) {
for (int m = 0; m < M; m++) {
float a = A[m][k]; // 在 N 维度上复用这次加载(可以理解为减少 GMEM 访问)
for (int n = 0; n < N; n++) {
C[m][n] += a * B[k][n];
}
}
}
如果这些加载来自 GMEM,那么通过将 A 的加载次数从 N^3 降低到 N^2,我们大约节省了 2× 的带宽。
但更重要的洞察在于算法层面:这种写法把 matmul 表达为一系列 外积(outer product)的部分和。这个视角对于理解接下来要讲的 warp-tiling 方法至关重要:
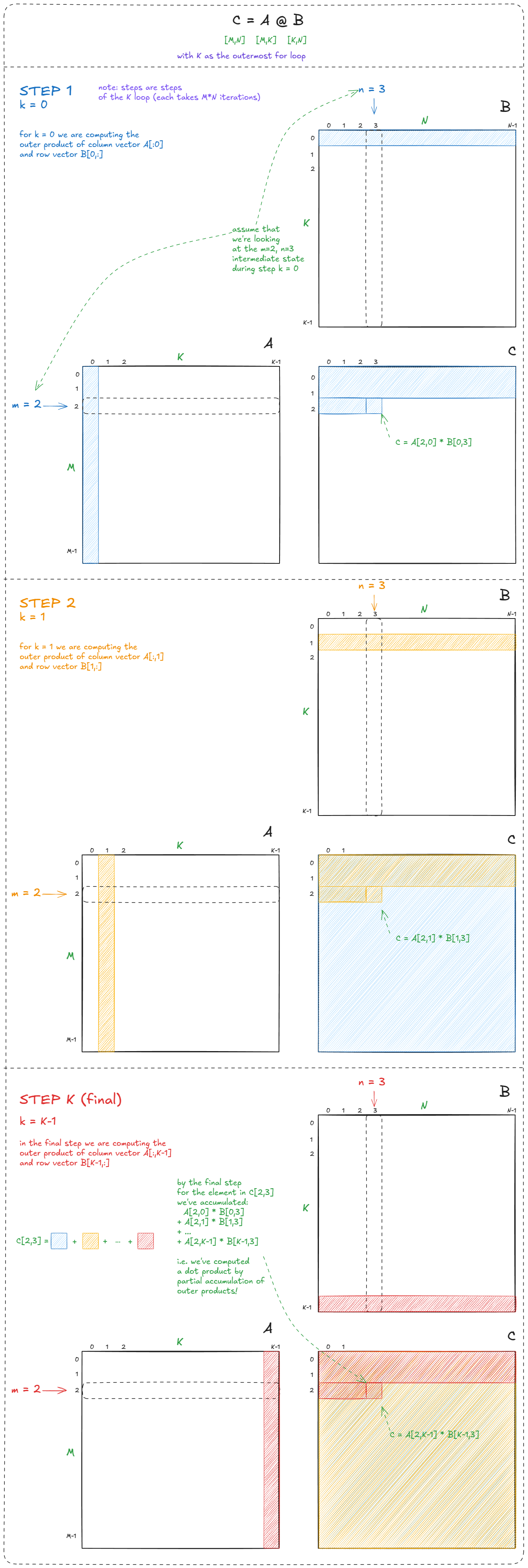
Figure 27: Matmul as a sum of partial outer products
这也许显而易见,但仍然值得强调:一个点积等价于若干个部分点积之和:

Figure 28: Dot product is equivalent to a sum of partial dot products
这之所以重要,是因为它允许我们把计算拆分为一系列块级 matmul(每个块产生部分点积)。通过在执行计算之前将这些块加载到 SMEM 中,我们可以显著减少 GMEM 流量,从而大幅提升性能。
如果不把计算分块处理,我们根本不可能把数据放进 SMEM。
还记得我们最初的 kernel 算术强度非常低——每加载一个字节所做的计算工作很少。要提升算术强度,我们需要做到两点:
- 让每个线程计算多个输出元素。
- 让输出 tile 尽可能接近正方形。
下面这张图直观地说明了为什么这很重要:
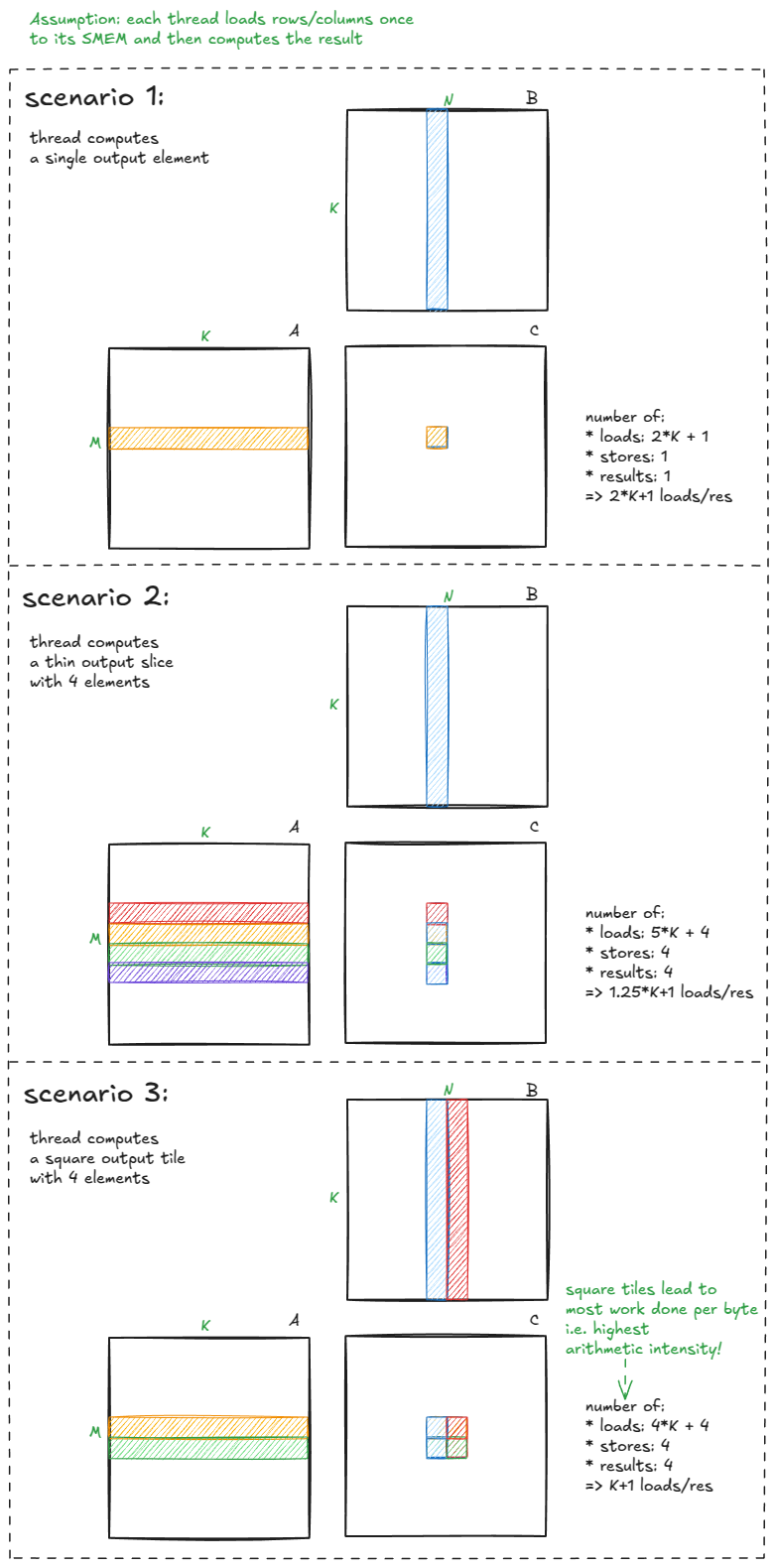
Figure 29: Arithmetic intensity improves when each thread computes multiple outputs and when tiles approach a square shape
到目前为止,我们已经收集了理解 warp-tiling 所需的大部分拼图,现在把它们组合起来。
我们已经知道两件关键的事情:
- 输出 tile 应尽可能为正方形(以最大化算术强度)。
- 计算应拆分为多个子步骤,使中间块能够放入 SMEM。
基于这一点,算法的高层结构如下所示:
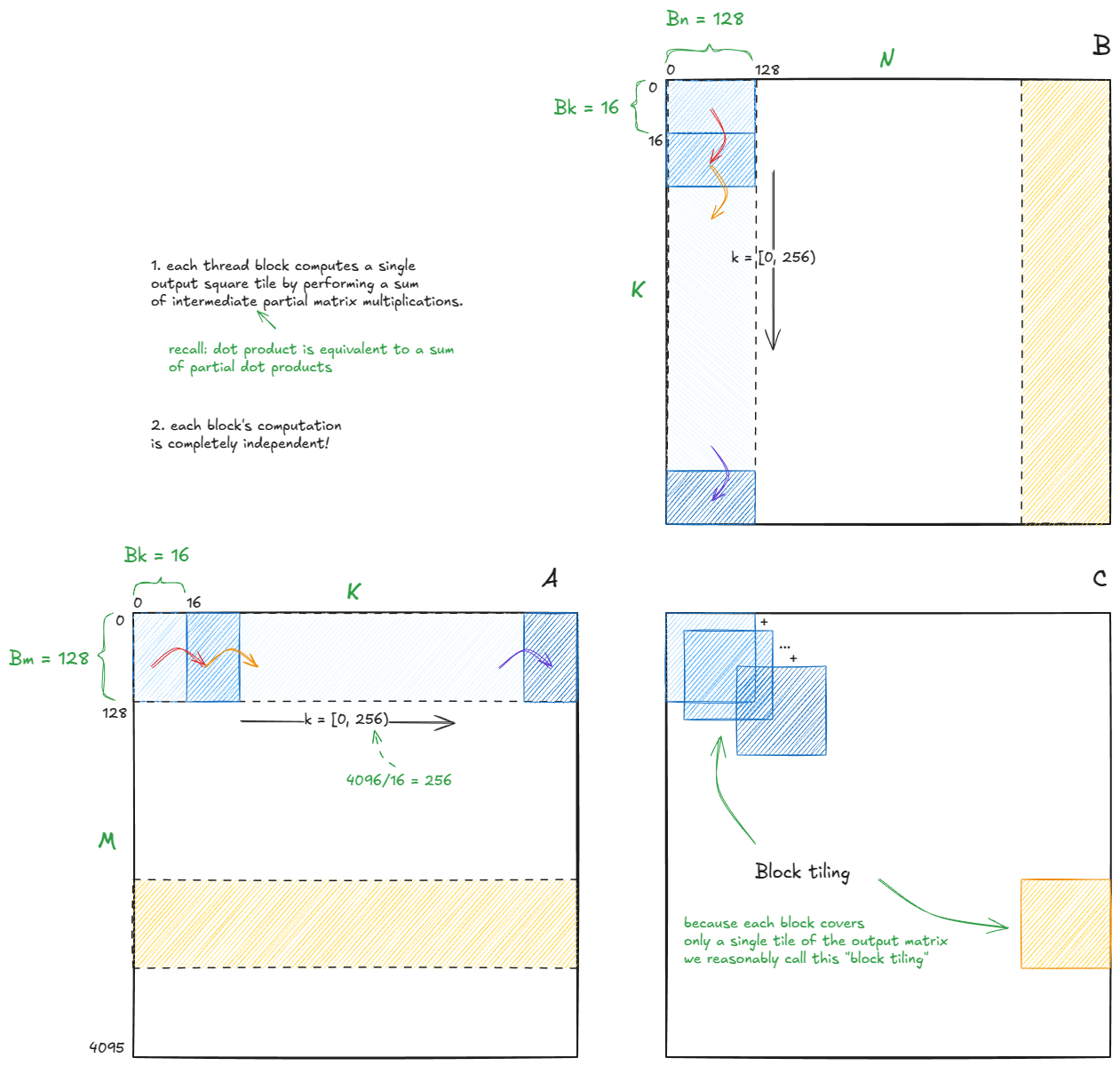
Figure 30: High-level structure of the warp-tiling algorithm, also referred to as block tiling.
参考代码在这里。我建议先看我的示意图,然后再打开代码,把所有细节串联起来。
📝Note:
我将使用与 Simon 博客中相同的 tile 尺寸(没有针对我的 H100 做自动调优):
Bm = Bn = 128, Bk = 16
由于每个 block 的计算是相互独立的——而我们已经确认部分点积会累加成完整的点积——因此我们只需要关注单个 block 的单个步骤。其他的(剩余的 1023 个 block,4096/128 * 4096/128 = 32 * 32 = 1024 个)都会遵循相同的逻辑。
📝Note to myself
不知为何我总是难以忽略其他 block。所以默念一遍:“其他一切都是正确的;我只需要专注于当前这一步。局部正确会导向全局正确。” :)
带着这种心态,我们放大到蓝色 block 的第一步(红色箭头切换之前的计算阶段),它对应输出 tile C[0,0](注意,是 tile,而不是单个元素)。
矩阵 A 的块尺寸为 Bm × Bk,矩阵 B 的块尺寸为 Bk × Bn。它们会被加载到 SMEM 缓冲区 As 和 Bs 中。
将 B 加载/存储到 Bs 相对直接,因为 Bs 没有做转置。4 个 warp 中的每一个都会从 GMEM 取一行 B,每个线程发出一次向量化加载(LDG.128),随后进行一次向量化存储(STS.128)。每个 warp 以 4 行为步长循环 4 次。
对应代码如下(我添加了注释,并移除了 Simon 注释掉的代码):
1
2
3
4
5
6
7
for (uint offset = 0; offset + rowStrideB <= BK; offset += rowStrideB) {
// 使用 reinterpret_cast 强制生成 LDG.128 指令(128b = 4 个 4B float)
reinterpret_cast<float4 *>(
&Bs[(innerRowB + offset) * BN + innerColB * 4])[0] =
reinterpret_cast<const float4 *>(
&B[(innerRowB + offset) * N + innerColB * 4])[0];
}
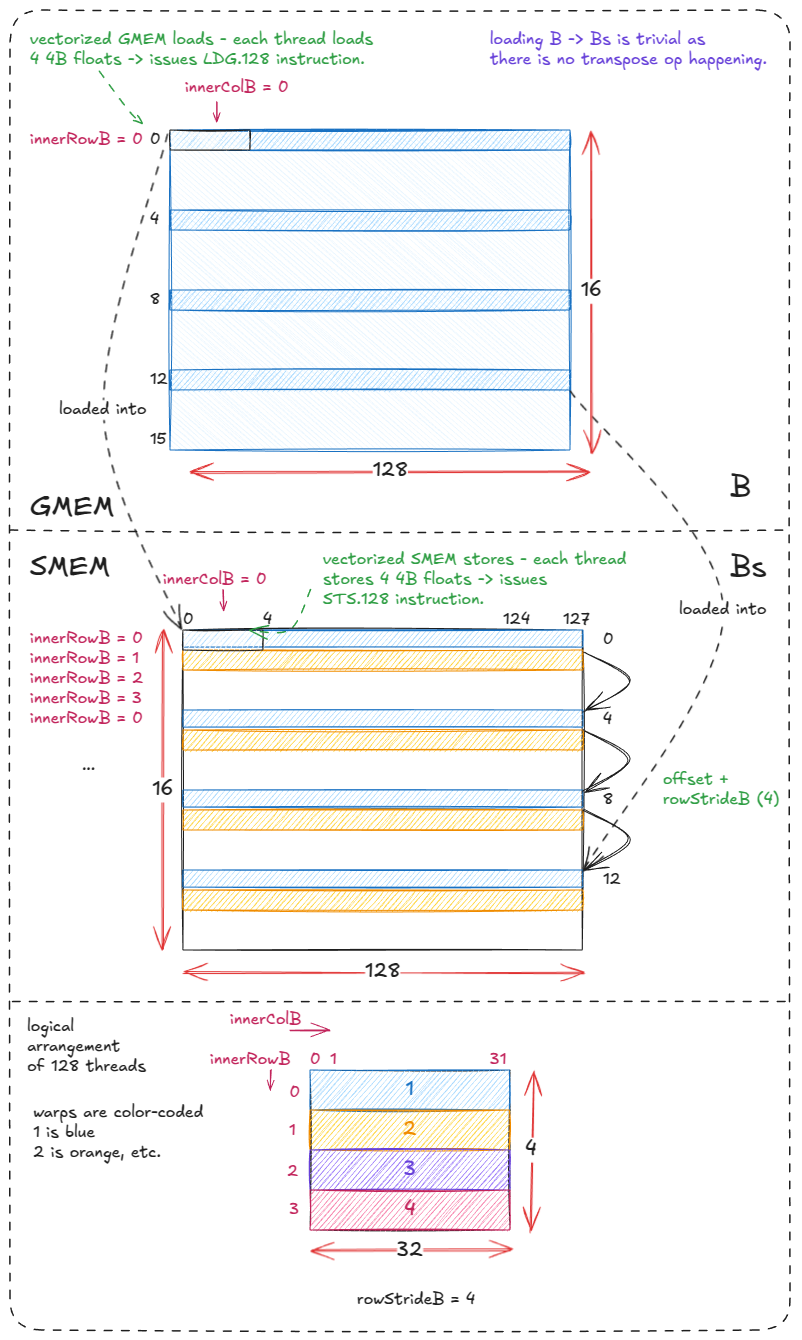
Figure 31: Loading a chunk of B (GMEM) into Bs (SMEM)
加载 A 到 As 则更复杂一些,因为 As 是转置存储的。之所以进行转置,是为了在后续计算阶段能够使用向量化加载(LDS.128)。
代价是存储无法向量化:从 A 的一行中取出的 4 个 float,现在必须被分散写入 As 的一列,而这一列映射到同一个 memory bank。这是可以接受的,因为我们优先优化加载性能——As 中的每个元素在计算阶段会被多次访问,而写入只发生一次。
图中的 innerRowX 和 innerColX 标注清楚地展示了每个线程负责的具体数据块。
对应代码如下:
1
2
3
4
5
6
7
8
9
for (uint offset = 0; offset + rowStrideA <= BM; offset += rowStrideA) {
// 使用 reinterpret_cast 强制生成 LDG.128 指令
const float4 tmp = reinterpret_cast<const float4 *>(
&A[(innerRowA + offset) * K + innerColA * 4])[0];
As[(innerColA * 4 + 0) * BM + innerRowA + offset] = tmp.x;
As[(innerColA * 4 + 1) * BM + innerRowA + offset] = tmp.y;
As[(innerColA * 4 + 2) * BM + innerRowA + offset] = tmp.z;
As[(innerColA * 4 + 3) * BM + innerRowA + offset] = tmp.w;
}
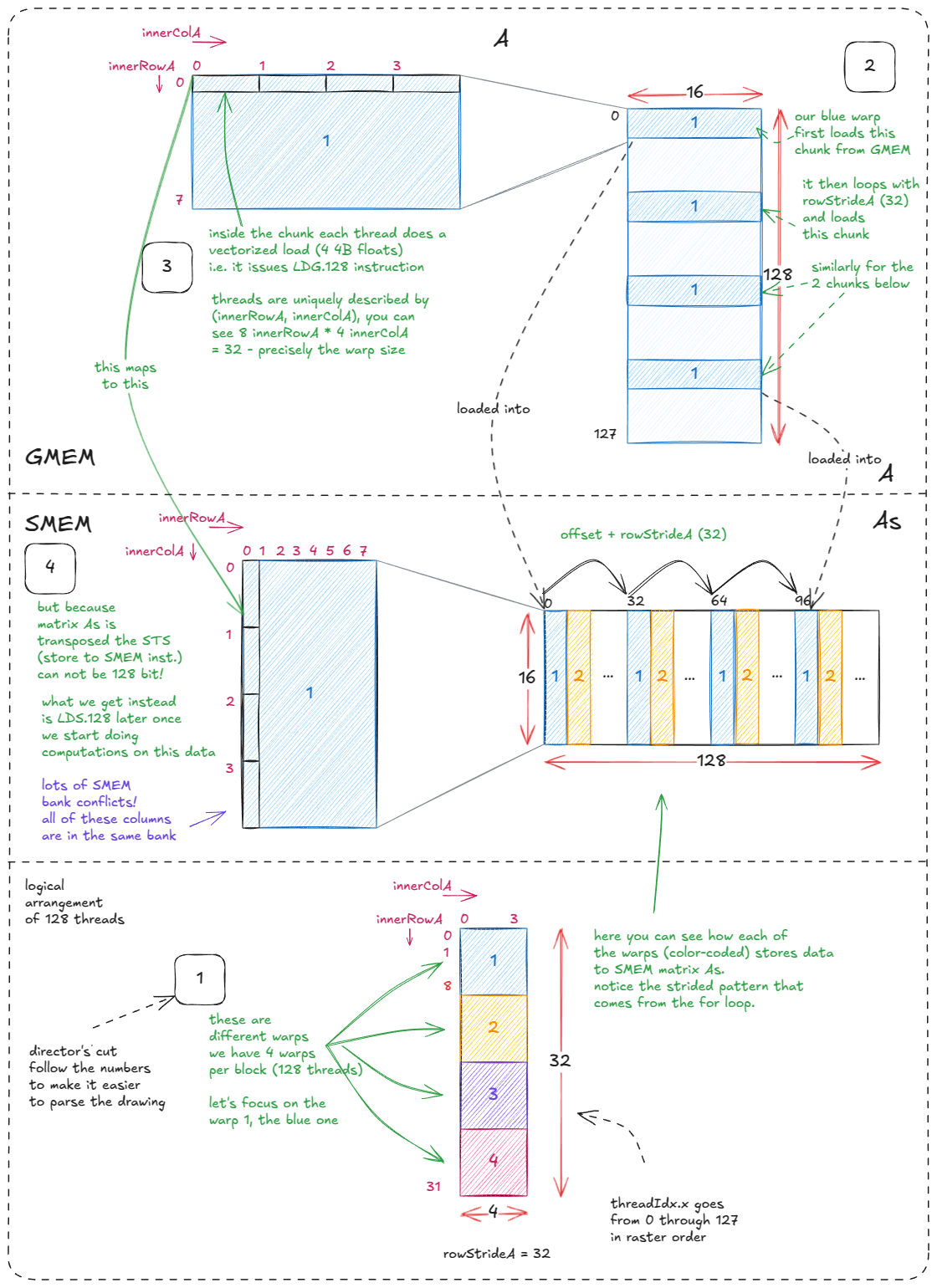
Figure 32: Loading a chunk of A (GMEM) into As (SMEM)
完成加载之后,我们对线程块进行同步(__syncthreads()),以确保 As 和 Bs 中的数据全部就绪。
接下来进入计算阶段。
对应代码如下(建议快速浏览代码,并在代码与示意图之间多对照几遍 :)):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
for (uint dotIdx = 0; dotIdx < BK; ++dotIdx) { // dotIdx 是最外层循环
// WM = 64,因此 As 被分成 2×64 的部分
// TM = 8,因此每个线程从 As 处理 8 行
// WMITER = 1,因此 As 中只有一个 slice(示意图附录中是 2 个)
for (uint wSubRowIdx = 0; wSubRowIdx < WMITER; ++wSubRowIdx) {
// 从 As 加载到寄存器 regM
for (uint i = 0; i < TM; ++i) {
regM[wSubRowIdx * TM + i] =
As[(dotIdx * BM) + warpRow * WM + wSubRowIdx * WSUBM +
threadRowInWarp * TM + i];
}
}
// WN = 64,因此 Bs 被分成 2×64 的部分
// TN = 4,因此每个 slice 有 4 列
// WNITER = 4,因此 Bs 中有 4 个 slice
// WSUBN = WN/WNITER = 16(用于遍历 slice)
for (uint wSubColIdx = 0; wSubColIdx < WNITER; ++wSubColIdx) {
for (uint i = 0; i < TN; ++i) {
// 从 Bs 加载到寄存器 regN
regN[wSubColIdx * TN + i] =
Bs[(dotIdx * BN) + warpCol * WN + wSubColIdx * WSUBN +
threadColInWarp * TN + i];
}
}
// 通过部分外积之和来执行 warptile matmul
for (uint wSubRowIdx = 0; wSubRowIdx < WMITER; ++wSubRowIdx) {
for (uint wSubColIdx = 0; wSubColIdx < WNITER; ++wSubColIdx) {
for (uint resIdxM = 0; resIdxM < TM; ++resIdxM) {
for (uint resIdxN = 0; resIdxN < TN; ++resIdxN) {
threadResults[(wSubRowIdx * TM + resIdxM) * (WNITER * TN) +
(wSubColIdx * TN) + resIdxN] +=
regM[wSubRowIdx * TM + resIdxM] *
regN[wSubColIdx * TN + resIdxN];
}
}
}
}
}
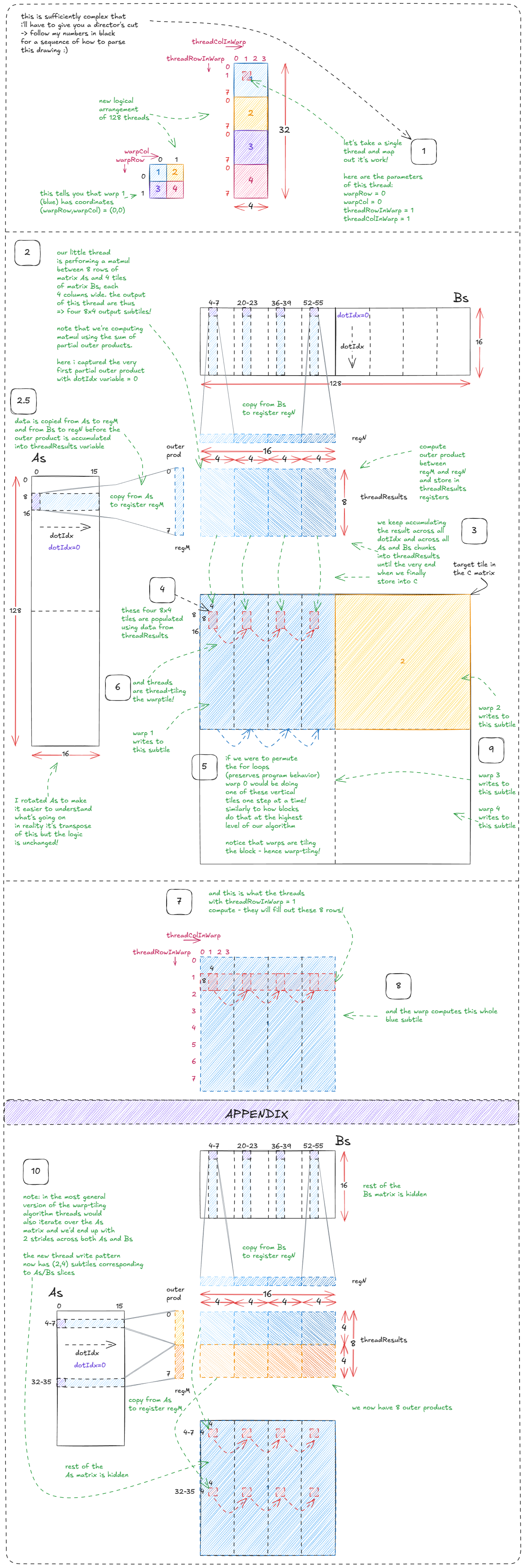
Figure 33: Performing matmul between As and Bs as a series of thread-level outer products (warp-tiling + thread-tiling).
Figure 33:以线程级外积的形式,在 As 和 Bs 之间执行 matmul(warp-tiling + thread-tiling)。
当这个 chunk 计算完成后,我们会再次进行同步。这一步是为了避免竞态条件——如果没有同步,有些线程可能已经开始把下一批 chunk 写入 As 和 Bs,而另一些线程还在处理当前的数据。
同步完成后,我们将 A 和 B 的指针分别向前移动 Bk,然后算法继续重复这一过程,直到所有 chunk 都被处理完为止。
1
2
A += BK; // 向右移动 BK 列
B += BK * N; // 向下移动 BK 行
最后,当外层循环结束时,这 128 个线程会把各自私有的 threadResults 寄存器中的结果,写回矩阵 C 中对应的输出 tile(此时这些结果已经是完整的点积值了!)。
在实际工程中,你通常会针对具体的 GPU 对该算法的参数进行 autotune。不过正如前面提到的,这种风格的 kernel 已经不再是首选方案——现代 GPU 拥有异步内存机制和 Tensor Core,其性能远远超出了单纯 warp-tiling 所能达到的水平。
接下来,我们进入 Hopper 上真正的 SOTA 实现。
📝下一章的补充阅读:
我强烈推荐 Pranjal 的优秀博客文章:blog post [15]。这篇文章更像是一份详细的工作日志。在本章中,我会沿着他 worklog 中的 kernel 继续展开。和 Simon 的工作类似,其中大量代码明显受到了 CUTLASS 的启发(例如这两篇文章:CUTLASS ping pong kernel [16] 以及 efficient GEMM)。
值得特别强调的是,细节决定成败,而 Pranjal 的实现甚至超越了 cuBLAS 的 SOTA——在若干目标矩阵尺寸上达到了约 107% 的 cuBLAS 性能。
在 Hopper 上设计 SOTA 级别的异步 matmul kernel
现在,我们要把所有硬件特性都用起来,在 Hopper 上真正达到 SOTA 水平。我们将使用:
- TMA 同步 load/store 操作
- Tensor Cores
- bf16 精度
这些硬件特性不仅极大简化了之前那种 warp-tiling 的手工复杂度,而且还能将性能提升将近一个数量级——Pranjal 报告称性能从 32 TFLOP/s 提升到 317 TFLOP/s,接近 10 倍提升。
📝参考代码:
这里我将以 kernel 2 [17] 作为参考(也可以查看我的 PR)。注意,这里的命名相较于 Simon 的版本略有变化:
As→sA,Bs→sB。
之所以能够实现这种简化,是因为 TMA 和 Tensor Cores 抽象掉了我们之前需要手动处理的大量底层细节。
作为迈向 Hopper SOTA 的第一步,我们先对之前的 warp-tiling baseline 进行修改。
我们保持完全相同的程序整体结构,只是做如下调整:
- 每个 thread block 现在只需要 128 个线程(4 个 warp)。
- tile 尺寸设为
BM = BN = BK = 64。
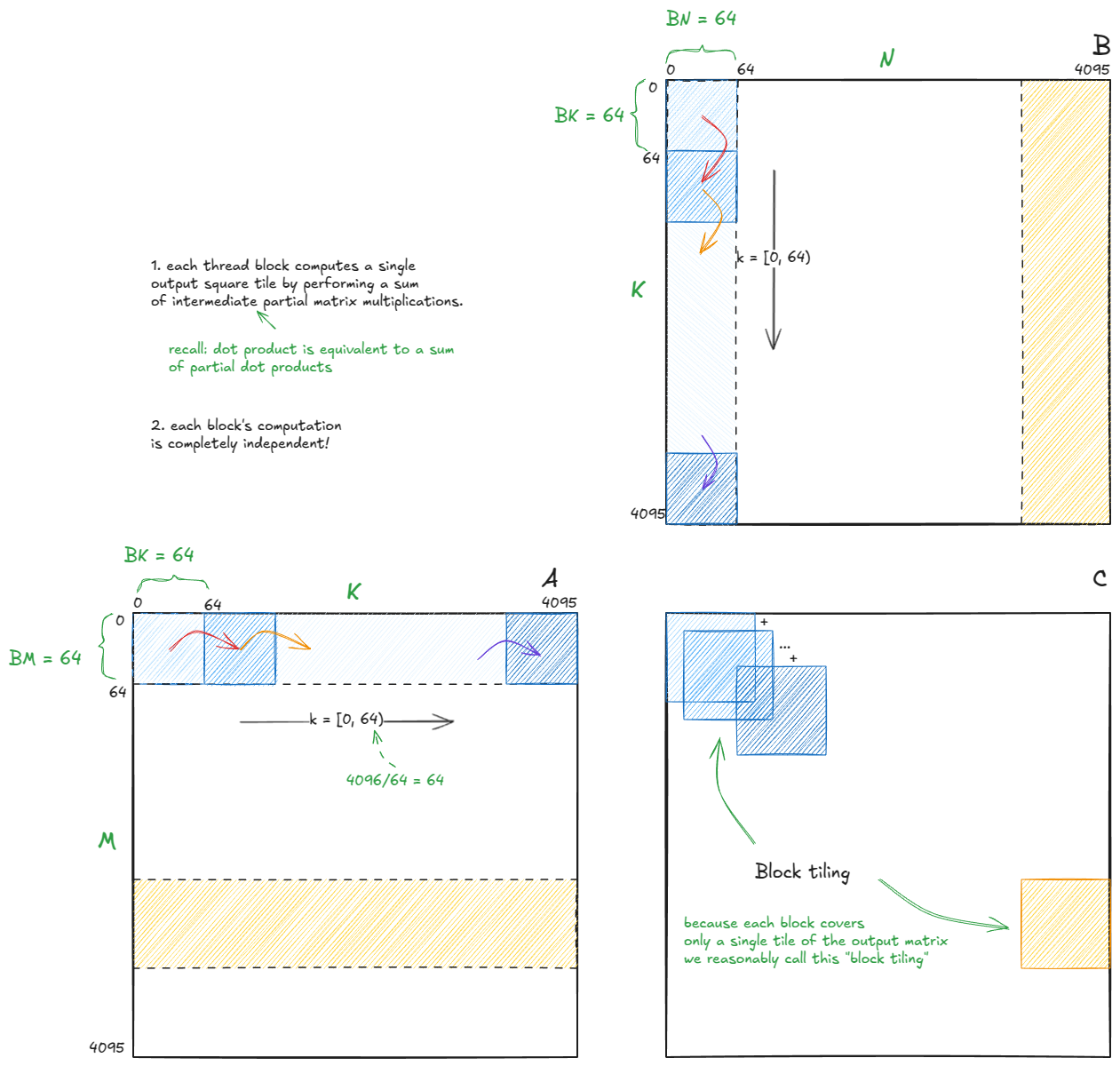
Figure 34: We keep the same high-level structure of the warp-tiling algorithm (block-tiling).
Figure 34:我们保持与 warp-tiling(block-tiling)相同的高层结构。
💡矩阵格式变更:
一个重要变化是:A 仍然采用 row-major 存储格式,而 B 现在改为 column-major 格式。
通过 TMA 异步加载到 SMEM
在第二阶段——将数据加载进 SMEM——TMA 用一种更为简单的方式,替代了之前那种复杂的 warp 级加载模式。我们只需要做三件事:
- 为
A和B构造 tensor map。 - 触发 TMA 操作(由 block 内的单个线程完成)。
- 使用 shared-memory barrier 进行同步。
TMA 不仅负责搬运数据,还会自动对数据进行 swizzling,从而解决我们在 warp-tiling 中遇到的 bank conflict 问题。(稍后我会专门用一节详细讲解 swizzling。)
为了构造 tensor map,我们使用 cuTensorMapEncodeTiled(参见 docs)。该函数会编码所有必要的元数据,用于将 A 和 B 的数据块从 GMEM 传输到 SMEM。我们需要分别为 A 和 B 构造一个 tensor map,不过它们在结构上是相同的。对于 A,我们指定:
- 数据类型:bf16
- Rank:2(矩阵)
- 指针:
A - 形状:
(K, M)(最快 stride 的维度在前) - 行步长:
K * sizeof(bf16) sA的形状:(BK, BM)- Swizzle 模式:在加载到
sA时使用 128B 模式
接下来是代码:
1
2
3
4
5
6
7
8
9
10
11
__shared__ barrier barA; // A 和 B 对应的 SMEM barrier
__shared__ barrier barB;
if (threadIdx.x == 0) {
// 用全部 128 个线程初始化 barrier
init(&barA, blockDim.x);
init(&barB, blockDim.x);
// 让初始化后的 barrier 对 async proxy 可见
cde::fence_proxy_async_shared_cta();
}
__syncthreads(); // 确保 barrier 对所有线程可见
这里我们初始化了 SMEM barrier,用于同步写入 sA 和 sB 的过程。barrier 使用全部 128 个线程进行初始化,因为我们期望 block 中的每一个线程都会在 barrier 变为“ready”状态之前到达该同步点。
cde::fence_proxy_async_shared_cta() 是 Hopper 代理内存模型的一部分。它在 CTA(block)作用域内,为“async proxy”(TMA)与“generic proxy”(普通线程的 ld/st)之间建立可见性顺序。在这里我们在初始化之后立即调用它,以确保异步引擎能够看到 barrier 的已初始化状态。(异步拷贝的完成将由 mbarrier 自身进行信号通知。)
完全坦白说:我也不敢声称自己完全理解所有内存一致性的细节——官方文档也并不算清晰。这或许值得单独写一篇文章深入讨论。如果你有好的学习资料推荐,欢迎联系我!
在外层的 K 循环中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
for (int block_k_iter = 0; block_k_iter < num_blocks_k; ++block_k_iter) {
if (threadIdx.x == 0) { // 只有一个线程发起 TMA
// 本 CTA 对应 tile 在 GMEM 中的偏移:
// A: (block_k_iter * BK, num_block_m * BM)
cde::cp_async_bulk_tensor_2d_global_to_shared(
&sA[0], tensorMapA, block_k_iter*BK, num_block_m*BM, barA);
// 更新 barrier,使其等待指定字节数后再翻转:
// sizeof(sA)
tokenA = cuda::device::barrier_arrive_tx(barA, 1, sizeof(sA));
// B: (block_k_iter * BK, num_block_n * BN)
cde::cp_async_bulk_tensor_2d_global_to_shared(
&sB[0], tensorMapB, block_k_iter*BK, num_block_n*BN, barB);
tokenB = cuda::device::barrier_arrive_tx(barB, 1, sizeof(sB));
} else {
tokenA = barA.arrive(); // 仅线程到达(不跟踪字节数)
tokenB = barB.arrive();
}
barA.wait(std::move(tokenA)); // 阻塞直到:所有线程到达 AND TMA 完成
barB.wait(std::move(tokenB));
下面我们按步骤梳理一下发生了什么(对 A 和 B 都是相同逻辑):
线程 0 调用 cp_async_bulk_tensor_2d_global_to_shared(...) 启动 TMA,指定 SMEM 目标地址(sA/sB)、tensor map,以及 GMEM 中的源数据偏移。
随后它立即调用 barrier_arrive_tx(bar, 1, sizeof(sX)),该调用会:
- 统计线程到达次数(这里是 1,来自线程 0),以及
- 为 barrier 设置一个预期字节数,以便它知道何时异步拷贝完成。
所有其他线程调用 bar.arrive(),贡献它们的到达次数(不涉及字节数)。
接着,每个线程都会调用 bar.wait(token)。只有当以下两个条件同时满足时,等待才会结束:
- 所有 128 个线程都已经到达;
- 异步引擎已经将
sizeof(sX)字节全部写入 shared memory。
这种加载模式是 Hopper 上的标准写法——在现代 kernel 中几乎随处可见。
在异步拷贝的过程中,TMA 还会使用 128B swizzle 格式对数据进行重排。
接下来,我们花一点时间来拆解一下 swizzling 到底是什么意思。我在网上并没有找到特别清晰的解释,所以这里给出我自己的理解——一半是写给你看的,一半是写给未来的自己。 :)
Swizzling
我们从一个直观的例子开始:
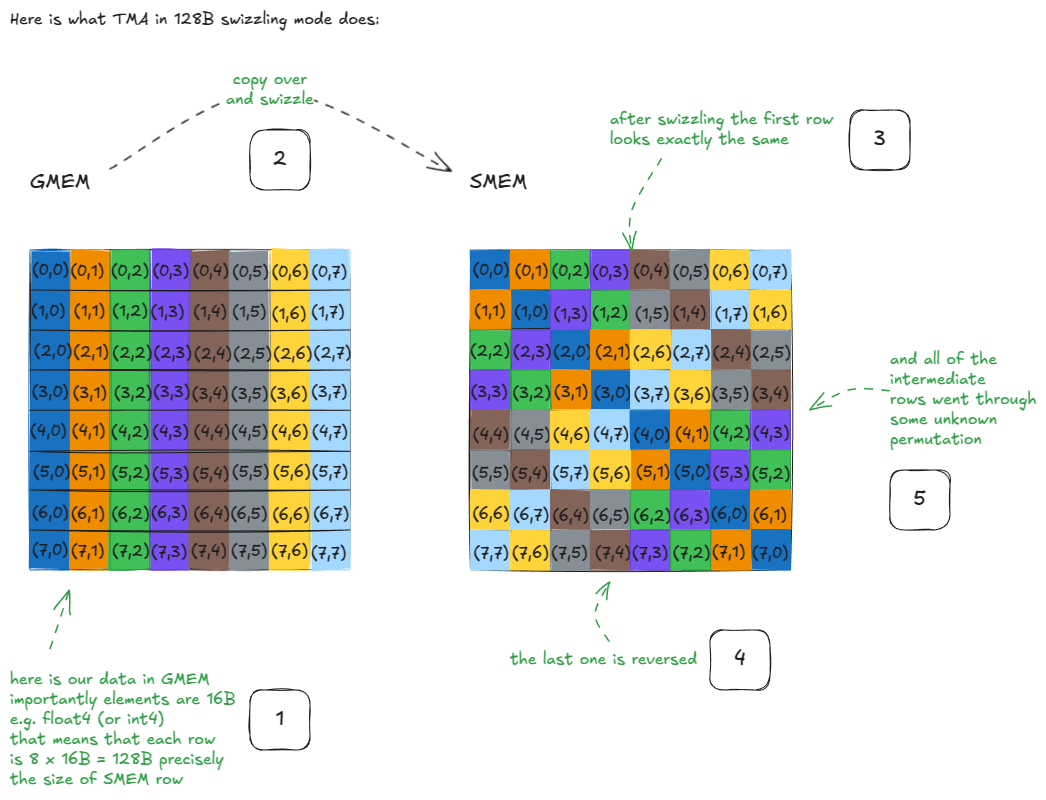
Figure 35: Swizzling example
Figure 35:Swizzling 示例
这里到底发生了什么?
假设我们想要加载原始 GMEM 矩阵的第一行所有元素。经过 swizzling 之后,这件事依然很简单:直接从 SMEM 矩阵的第一行读取即可。没有什么特别之处。
现在,假设我们想读取原始 GMEM 矩阵的第一列。请注意,这些元素在 SMEM 中现在沿着对角线分布。这意味着我们可以在一个周期内完成加载,因为不会有两个线程访问同一个 bank——零 bank conflict。
如果没有 swizzling,这种访问方式会把整列元素映射到同一个 bank,只是地址不同,从而产生 8-way bank conflict,吞吐量会被直接砍到原来的 1/8。
而在 swizzling 之后,这种性质对任意一行或一列都成立:无论是行访问还是列访问,都可以在单个周期内完成!
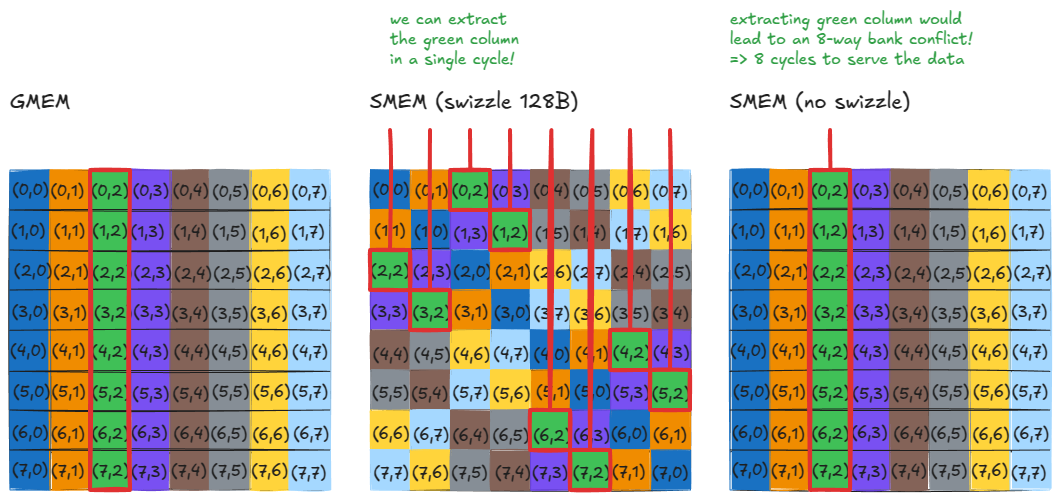
Figure 36: No bank conflicts when loading rows or columns
Figure 36:加载行或列时都不会产生 bank conflict
同样的性质也适用于 store 操作。例如,如果你想在 SMEM 中对一个矩阵进行转置,最朴素的方法是:读取一整行,然后把它写回为一整列。在没有 swizzling 的情况下,这会导致 8-way bank conflict。
开启 swizzling 之后,这个问题就被规避了,不过在编写索引时你仍然需要格外小心。
📝Note
当数据从 SMEM 再搬回 GMEM 时,TMA 会自动对其进行 unswizzle。
既然动机已经清楚,我们可以继续问一个问题:TMA 是如何实际生成这种 swizzle 模式的?
答案其实很简单:通过与一个特定的 mask 模式进行 XOR 运算。
简要回顾一下 XOR 的真值表:
- 0, 0 → 0
- 0, 1 → 1
- 1, 0 → 1
- 1, 1 → 0
关键点在于:当其中一个 bit 为 1 时,XOR 会翻转另一个 bit。
和往常一样,我们可以在 CUTLASS 的源码中找到答案。另外一位 Simon(不是前面提到的那位)也对 mask 模式的生成方式给出了非常不错的解释:generated [18]。不过,他并没有详细说明这个模式是如何进一步导出我们刚才看到的具体 swizzle 布局。
因此,还剩下两个关键问题:
- XOR 的 mask 是如何生成的?
- 这个 mask 是如何实际应用,从而形成具体的 swizzle 模式的?
生成 XOR mask
NVIDIA 将每种 swizzle 模式关联到一个特定的“swizzle 函数”:
- 128B swizzle 模式对应
Swizzle<3,4,3> - 64B swizzle 模式对应
Swizzle<2,4,3> - 32B swizzle 模式对应
Swizzle<1,4,3>
我们先来拆解 Swizzle<3,4,3>,随后我会分享其他模式对应的 XOR mask。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
// 为了提高可读性,我用下划线把位分组为 8 位
// Swizzle<3, 4, 3>
// -> BBits = 3
// -> MBase = 4
// -> SShift = 3
// 根据上面解析出来的参数,swizzle 函数执行的步骤如下:
// Step 1. 计算 bit_msk = (1 << BBits) - 1
bit_msk = (0b00000000_00000001 << 3) - 1 = 0b00000000_00000111 // 保留 16 位分辨率
// Step 2. 计算 yyy_msk = bit_msk << (MBase + max(0, SShift))
yyy_msk = 0b00000000_00000111 << 7 = 0b00000011_10000000
// Step 3. 对输入数进行掩码(为清晰起见标注位 A-P)
input_number = 0bABCDEFGH_IJKLMNOP
masked = input_number & yyy_mask
= 0bABCDEFGH_IJKLMNOP & 0b00000011_10000000 = 0b000000GH_I0000000
// Step 4. 右移 SShift 位 (masked >> SShift)
shifted = masked >> 3
= 0b000000GH_I0000000 >> 3 = 0b00000000_0GHI0000
// Step 5. 与原始输入 XOR
output = input_number ^ shifted
= 0bABCDEFGH_IJKLMNOP ^ 0b00000000_0GHI0000 = 0bABCDEFGH_IwyzMNOP
// 为了易读,将未改变的位用 x 表示。
// 我也把 "wyz" 大写以突出,同时保留 GHI 因为它们会影响 wyz:
output = 0bxxxxxxGH_IWYZxxxx
// 其中 WYZ = GHI ^ JKL (XOR)
通俗地说:swizzle 函数会观察 GHI 三个位(零索引下的第 9、8、7 位)。如果这些位中任意一个为 1,它就会翻转对应的 JKL 三个位(第 6、5、4 位),得到 WYZ。其他位保持不变。
我们可以通过直观图理解 swizzle 函数的行为:

Figure 37: Swizzle function intuition
Figure 37:Swizzle 函数直观示意
对于 32B 和 64B swizzle 模式,swizzle 函数分别为 0bxxxxxxxx_IxxZxxxx 和 0bxxxxxxxH_IxYZxxxx。
它们遵循相同的“与 mask XOR”思路,只是控制位不同,从而决定哪些低位会被翻转。
那么,这一切如何回到我们最初的动机示例?
关系如下:
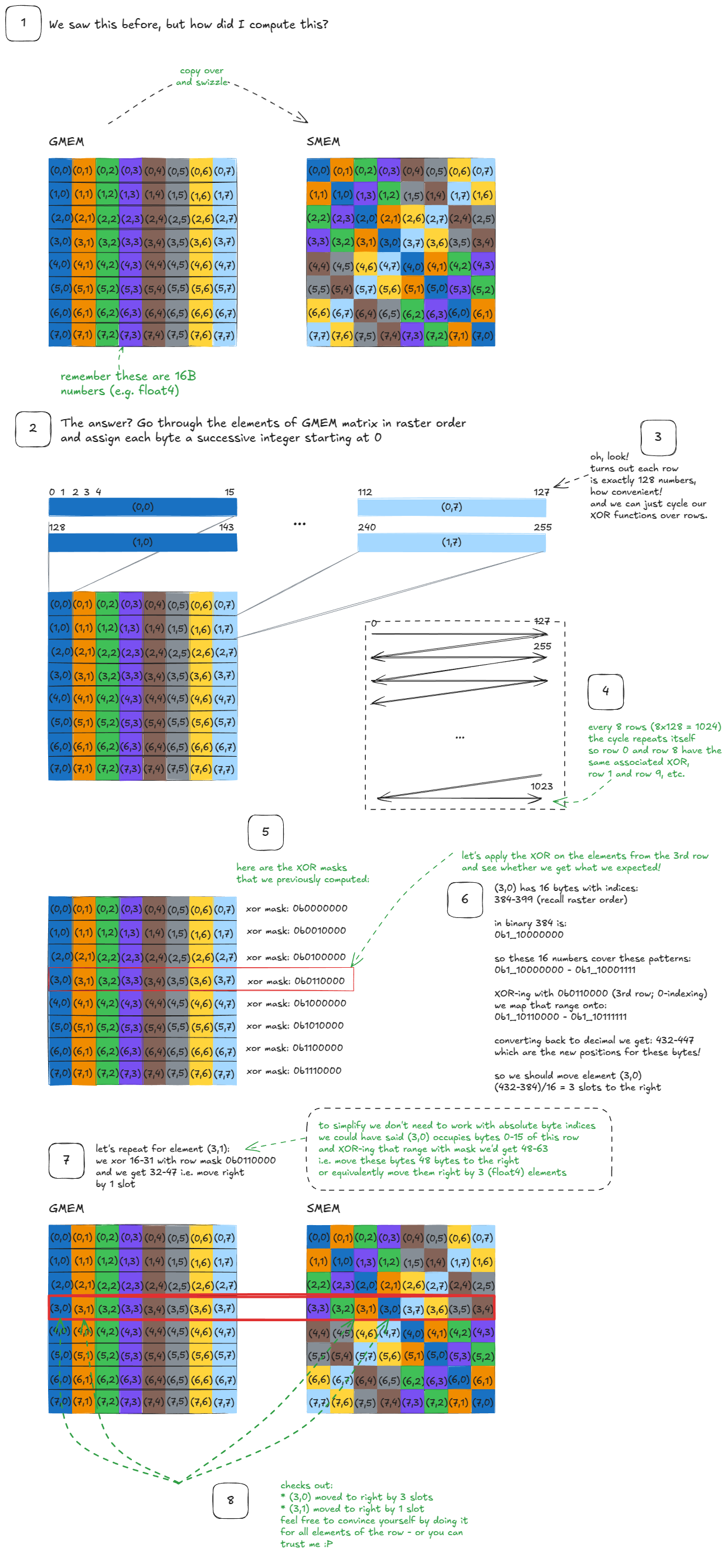
Figure 38: Connecting the swizzle function to the matrix swizzle example
Figure 38:将 swizzle 函数与矩阵 swizzle 示例关联
到此,我们就理解了 swizzling 的原理(WHY)和实现方式(HOW)。 :)
张量核心(Tensor Cores)
回到张量核心。此时,我们已经把来自 GMEM 的 A 和 B 块加载到 SMEM 中的 sA 和 sB 里。它们已经经过 swizzle,并且准备好供张量核心使用。
NVIDIA 提供了几种矩阵乘加(MMA)指令:
wmma— warp 协作,同步(老一代)。mma.sync— warp 协作,同步(Ampere)。wgmma.mma_async— warp 组协作,异步(Hopper)。
📝注意: 一个 warp 组 = 4 个 warps = CUDA 中的 128 个线程。
我们将重点关注 wgmma.mma_async (文档 [19]),因为它是 Hopper 引入的最强大指令。它是异步的,利用 4 个协作 warp 一起计算矩阵乘法;这正是我们选择块大小 = 128 的原因。
对于 bf16 操作数,wgmma 支持 m64nNk16 形式的形状,其中 N ∈ {8, 16, 24, …, 256}。在当前示例中,我们使用 m64n64k16,但通常更大的 N 可以带来更高性能(前提是有足够的寄存器和 SMEM 支撑)。
📝注意:
m64n64k16表示张量核心一次性计算64×16×16×64的矩阵乘法。
操作数的放置规则如下:sA 可以在寄存器或 SMEM 中,sB 必须在 SMEM 中,累加器(BM x BN)总是在寄存器中。
由于单个线程无法容纳这么多寄存器,累加器被分配到 warp 组的各个线程中。
在我们的参考 kernel 中,你会看到累加器初始化如下:
1
2
float d[WGMMA_N/16][8]; // d 是累加器;GEMM: D = A @ B + D
memset(d, 0, sizeof(d)); // 初始化为 0
我们设定 WGMMA_M = WGMMA_N = BM = BN = 64。这样:
- warp 组有 128 个线程
- 每个线程持有
WGMMA_N/16 × 8个寄存器 - 总计:128 × (64/16) × 8 = 64 × 64 个寄存器
…这正好匹配累加器大小(BM × BN = 64 × 64),只是分布在整个组中。
下面是对应的张量核心调用片段,我们将分解它:
1
2
3
4
5
6
7
asm volatile("wgmma.fence.sync.aligned;" ::: "memory");
wgmma64<1, 1, 1, 0, 0>(d, &sA[0], &sB[0]);
wgmma64<1, 1, 1, 0, 0>(d, &sA[WGMMA_K], &sB[WGMMA_K]);
wgmma64<1, 1, 1, 0, 0>(d, &sA[2*WGMMA_K], &sB[2*WGMMA_K]);
wgmma64<1, 1, 1, 0, 0>(d, &sA[3*WGMMA_K], &sB[3*WGMMA_K]);
asm volatile("wgmma.commit_group.sync.aligned;" ::: "memory");
asm volatile("wgmma.wait_group.sync.aligned %0;" ::"n"(0) : "memory");
📝注意事项:
首先来看包围实际矩阵乘调用的开头和结尾指令(wgmma.fence、commit_group、wait_group)。
wgmma.fence.sync.aligned; — 文档 解释得很清楚:“wgmma.fence 建立先前对任何 warpgroup 寄存器访问与随后的 wgmma.mma_async 指令访问相同寄存器之间的顺序关系。”
实际上,warp 组中的四个 warp 都必须在执行第一个 wgmma.mma_async 之前执行 fence。
之后,我们就可以放心执行 MMA。即使累加器寄存器在四次 wgmma 调用间被更新,也不需要额外 fence — 对同一形状连续累加到相同寄存器的 MMA,有专门的例外。正好就是我们这里的情况。
这部分其实就是样板指令。如果注释掉,编译器会悄悄帮你加回来。
wgmma.commit_group — 另一条样板操作:文档:“将所有之前未提交的 wgmma.mma_async 操作提交为一个 wgmma 组。” 它把我们刚发出的四次调用合并成一个组。
wgmma.wait_group 0 — 表示:在继续执行前,等待所有先前的组完成。这里只有一个组,所以意思是“等待这四次 MMA 完成,结果已经写入累加器寄存器”。
标准节奏是:fence → 发起一批异步 MMA → commit → 等待完成。
接下来是 wgmma 本身。wgmma64 函数封装了内联 PTX 调用:
1
wgmma.mma_async.sync.aligned.m64n64k16.f32.bf16.bf16
Opcode 的结构比较直观:f32 是累加器数据类型,bf16 是输入矩阵 sA 和 sB 的数据类型。
语义就是标准的 FMA:D = A @ B + D,即在现有 fp32 tile 上累加 GEMM。(有个标志可以改成 D=A @ B,后面会用到。)
我刻意跳过
sA和sBSMEM 描述符的构造细节。描述符包含 SMEM 基地址、swizzle 模式(本例 128B)以及LBO/SBO(行/列字节偏移)信息,确保张量核心能正确寻址布局。这里讲描述符构造会让文章更冗长,可以单独写一篇。只需知道有这一层元数据即可。
下面解释为什么我们需要四次 wgmma 调用:
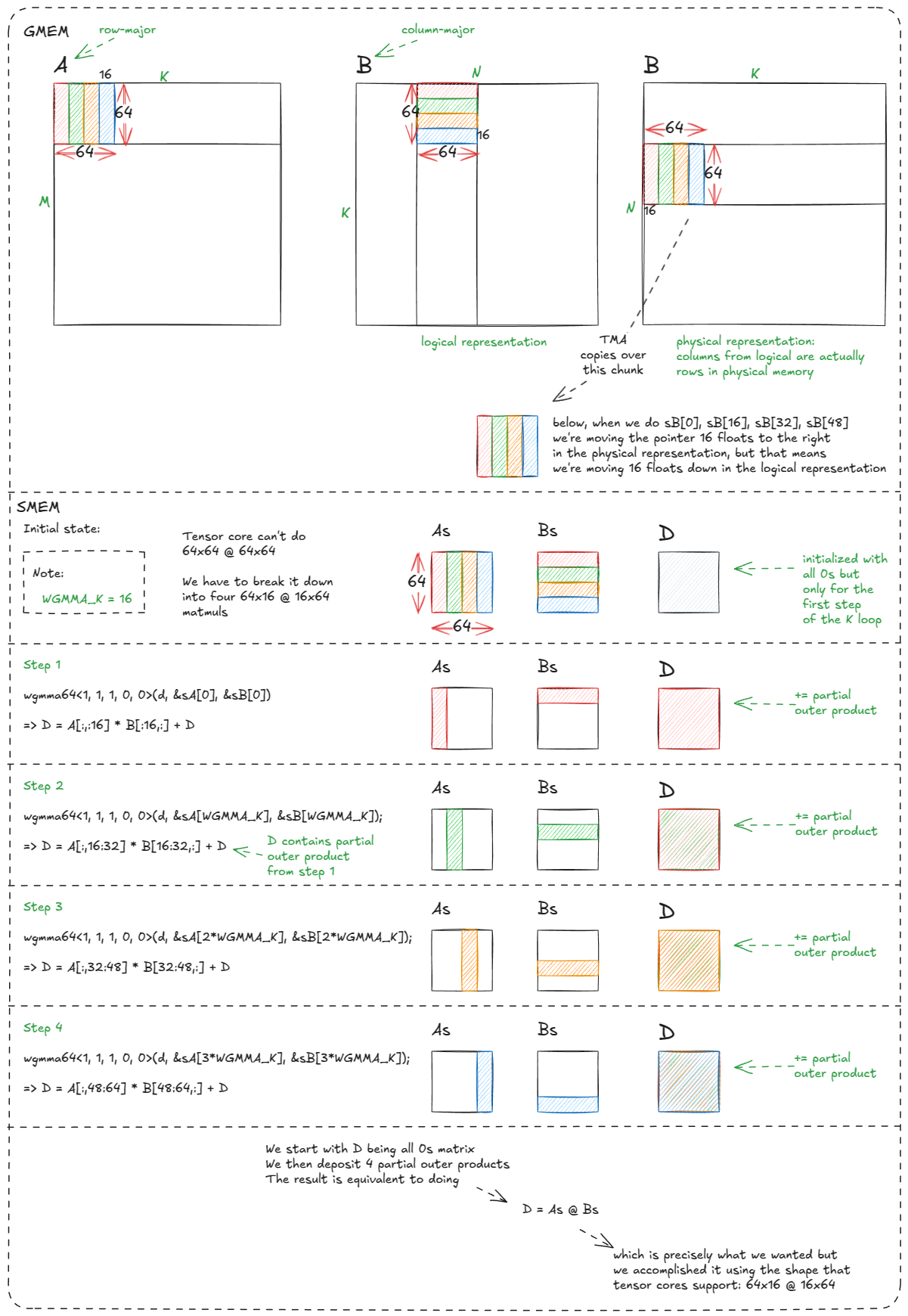
Figure 39: Why doing four 64x16 @ 16x64 wgmma calls is equivalent to doing a 64x64 @ 64x64 matmul
Figure 39:为什么四次 64x16 @ 16x64 的 wgmma 调用等价于一次 64x64 @ 64x64 矩阵乘法
稍微令人费解的是列优先表示法:sB[0] … sB[48] 如何映射到正确的逻辑位置/切片。
但关键结论是,之前 warp-tiling 和 thread-tiling 的复杂操作,现在硬件抽象掉了。曾经需要 warp 间精心协调的操作,现在只需少量样板指令和几次声明式 wgmma 调用。
话虽如此,这只是起点。我们仍然浪费了 TMA 和张量核心周期:
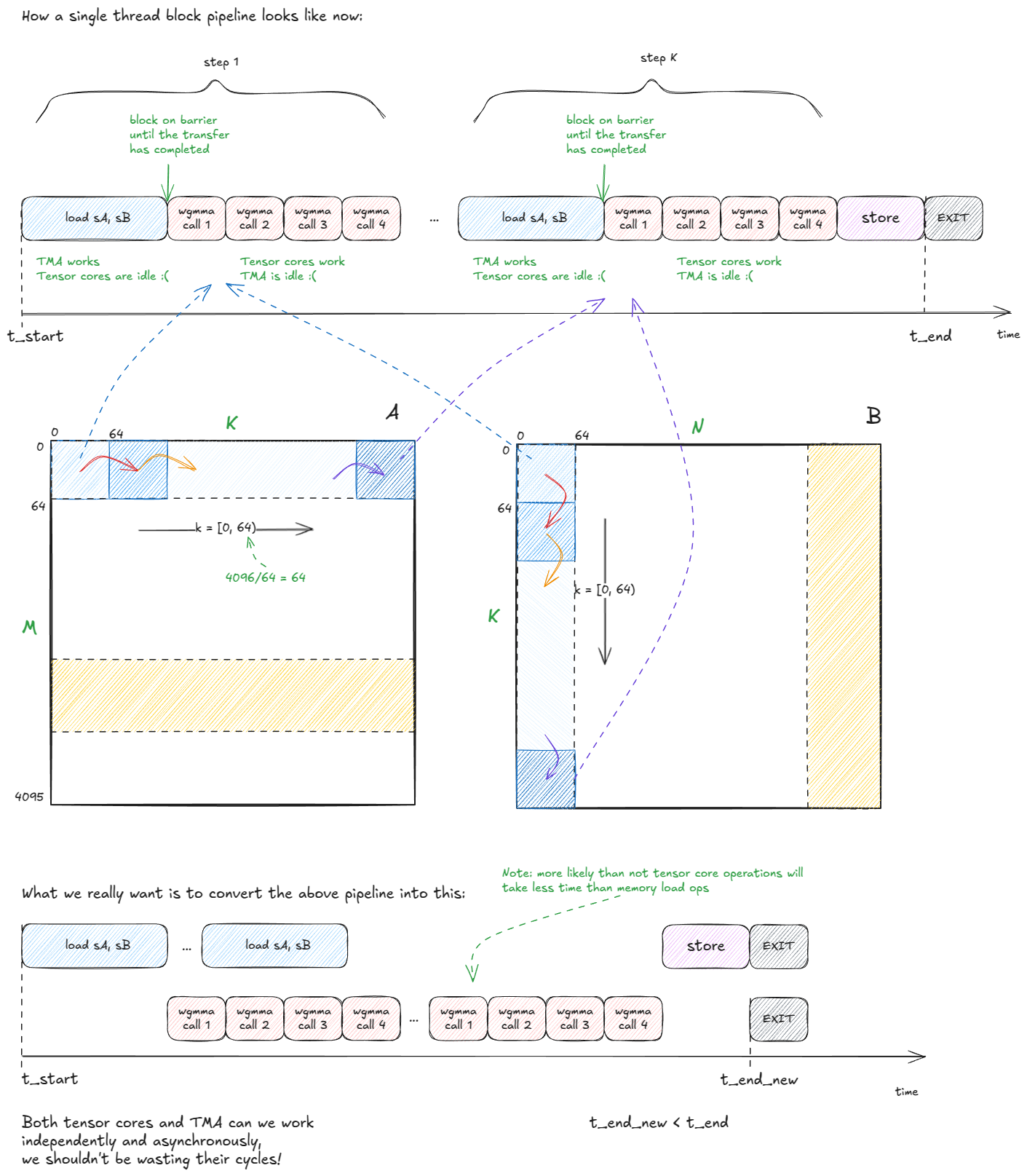
Figure 40: We are wasting TMA and TC cycles - we can do better
Figure 40:我们浪费了 TMA 和张量核心周期 —— 还有优化空间
我们解决浪费周期的方法是将计算和数据移动进行流水线化。具体来说,我们把 sA 和 sB(驻留在 SMEM 的 tile)变成一个块队列——比如长度为 5 的队列。
然后我们把工作分配给两个 warp 组:
- 一个 warp 组作为
producer,负责让 TMA 保持忙碌,通过流式方式将新的A和B块填入队列。 - 另一个 warp 组作为
consumer,从队列中取出块,保持张量核心的饱和运算。
自然,这需要协调。我们使用的机制是在 SMEM 中建立一个屏障队列,每个队列槽对应一对 full[i]/empty[i] 屏障,用于同步 producer 和 consumer。
参考:kernel 4 代码。
初始化如下:
1
2
3
4
// 队列屏障
__shared__ barrier full[QSIZE], empty[QSIZE];
// 使用可用的最大 MMA 形状
constexpr int WGMMA_M = 64, WGMMA_K = 16, WGMMA_N=BN;
初始化方式和之前类似:
1
2
3
4
5
6
7
8
9
10
if (threadIdx.x == 0) {
for (int i = 0; i < QSIZE; ++i) {
// num_consumers == 1 在本例中
// 128 个 consumer warp 线程 + 1 个 producer 线程
init(&full[i], num_consumers * 128 + 1);
init(&empty[i], num_consumers * 128 + 1);
}
cde::fence_proxy_async_shared_cta(); // 同前
}
__syncthreads(); // 同前
需要注意两点:
- 我们把张量核心 MMA 升级到更大的形状(从
m64n64k16到m64nBNk16),实测可以最大化计算吞吐。 - 由于队列是多槽的,屏障初始化必须遍历所有槽。
主逻辑如下:
- 在 producer(
wg_idx = 0)中,一个线程协调 TMA 将块复制到队列。它使用empty[qidx].wait()阻塞,直到某个缓冲区空闲,然后对sA和sB调用cp_async_bulk_tensor_2d_global_to_shared。最后,通过barrier_arrive_tx标记完成,将屏障与复制字节数绑定。 - 在 consumer(
wg_idx > 0)中,所有线程先把每个队列槽标记为空(准备填充)。然后每个K步,它们等待full[qidx],对缓冲区执行张量核心 MMA,完成后再次标记该槽为空。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
// Producer
if (wg_idx == 0) { // wg_idx = threadIdx.x / 128
if (tid == 0) { // 仅线程 0 发起 TMA 调用
int qidx = 0; // 环形缓冲索引
for (int block_k_iter = 0; block_k_iter < num_blocks_k; ++block_k_iter, ++qidx) {
if (qidx == QSIZE) qidx = 0; // 环回
empty[qidx].wait(empty[qidx].arrive()); // 等待缓冲区空闲
cde::cp_async_bulk_tensor_2d_global_to_shared(
&sA[qidx*BK*BM], tensorMapA, block_k_iter*BK, num_block_m*BM, full[qidx]);
cde::cp_async_bulk_tensor_2d_global_to_shared(
&sB[qidx*BK*BN], tensorMapB, block_k_iter*BK, num_block_n*BN, full[qidx]);
barrier::arrival_token _ = cuda::device::barrier_arrive_tx(
full[qidx], 1, (BK*BN+BK*BM)*sizeof(bf16)); // 非阻塞标记字节数
}
}
} else {
// Consumer warp-group
for (int i = 0; i < QSIZE; ++i) {
barrier::arrival_token _ = empty[i].arrive(); // 所有 128 个 consumer 线程标记空
}
float d[BM/WGMMA_M][WGMMA_N/16][8]; // 分布式累加器寄存器,初始化为 0
memset(d, 0, sizeof(d));
int qidx = 0;
for (int block_k_iter = 0; block_k_iter < num_blocks_k; ++block_k_iter, ++qidx) {
if (qidx == QSIZE) qidx = 0; // 环回
full[qidx].wait(full[qidx].arrive()); // 等待 TMA 完成填充
warpgroup_arrive(); // PTX 样板封装
#pragma unroll
for (int m_it = 0; m_it < BM/WGMMA_M; ++m_it) {
bf16 *wgmma_sA = sA + qidx*BK*BM + BK*m_it*WGMMA_M;
#pragma unroll
for (int k_it = 0; k_it < BK/WGMMA_K; ++k_it) {
wgmma<WGMMA_N, 1, 1, 1, 0, 0>(
d[m_it], &wgmma_sA[k_it*WGMMA_K], &sB[qidx*BK*BN + k_it*WGMMA_K]);
}
}
warpgroup_commit_batch();
warpgroup_wait<0>();
barrier::arrival_token _ = empty[qidx].arrive(); // 标记缓冲区已消费
}
// 最后:将累加器 d 写回输出矩阵 C
}
可视化如下,便于理解:
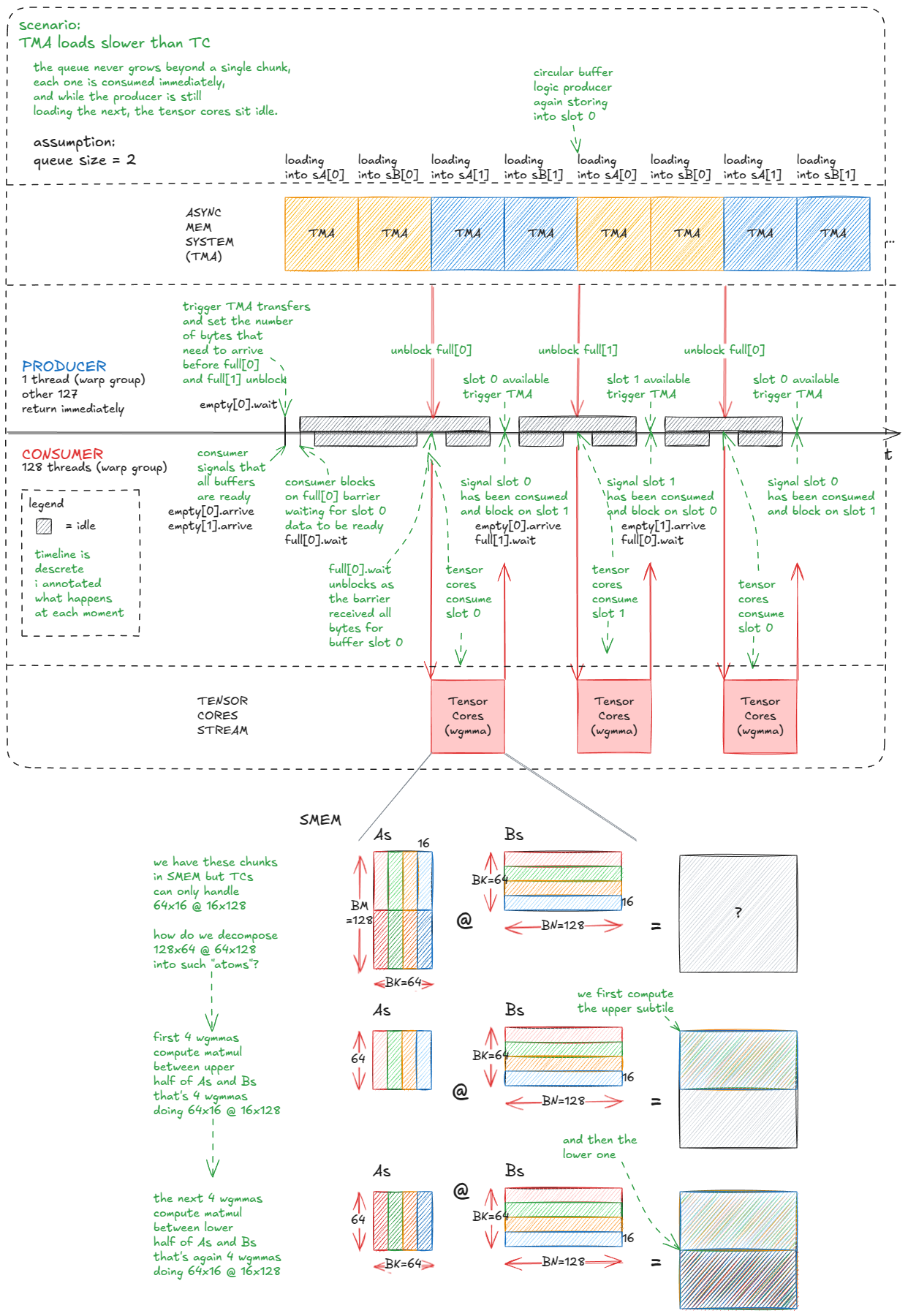
Figure 41: More efficient TC/TMA pipeline: producer warp-group streams tiles into a circular buffer; consumer warp-group drains tiles into tensor cores.
Figure 41:更高效的 TC/TMA 流水线:producer warp 组将 tile 流入环形缓冲区;consumer warp 组将 tile 消耗到张量核心。
一个自然的优化是把输出 tile 从 128×128 增大到 128×256。问题是,这样每个 consumer warp 组中每个线程的累加器片段变得太大——每个线程单独持有 256 个 fp32 寄存器,仅用于累加器,超过单线程寄存器预算(触发寄存器溢出到设备内存,性能严重下降)。
解决方案是增加一个 consumer warp 组,把累加器分片到两个组而不是一个。我们保留单个 producer(驱动 TMA),整个块/CTA 启动 3×128 = 384 个线程:
- WG0:producer(TMA)
- WG1:consumer A(计算 128×256 tile 上半部分)
- WG2:consumer B(计算下半部分)
每个 consumer 拥有输出的 64×256 半 tile,因此每个线程累加器占用减半,避免寄存器溢出。
执行流程如下:
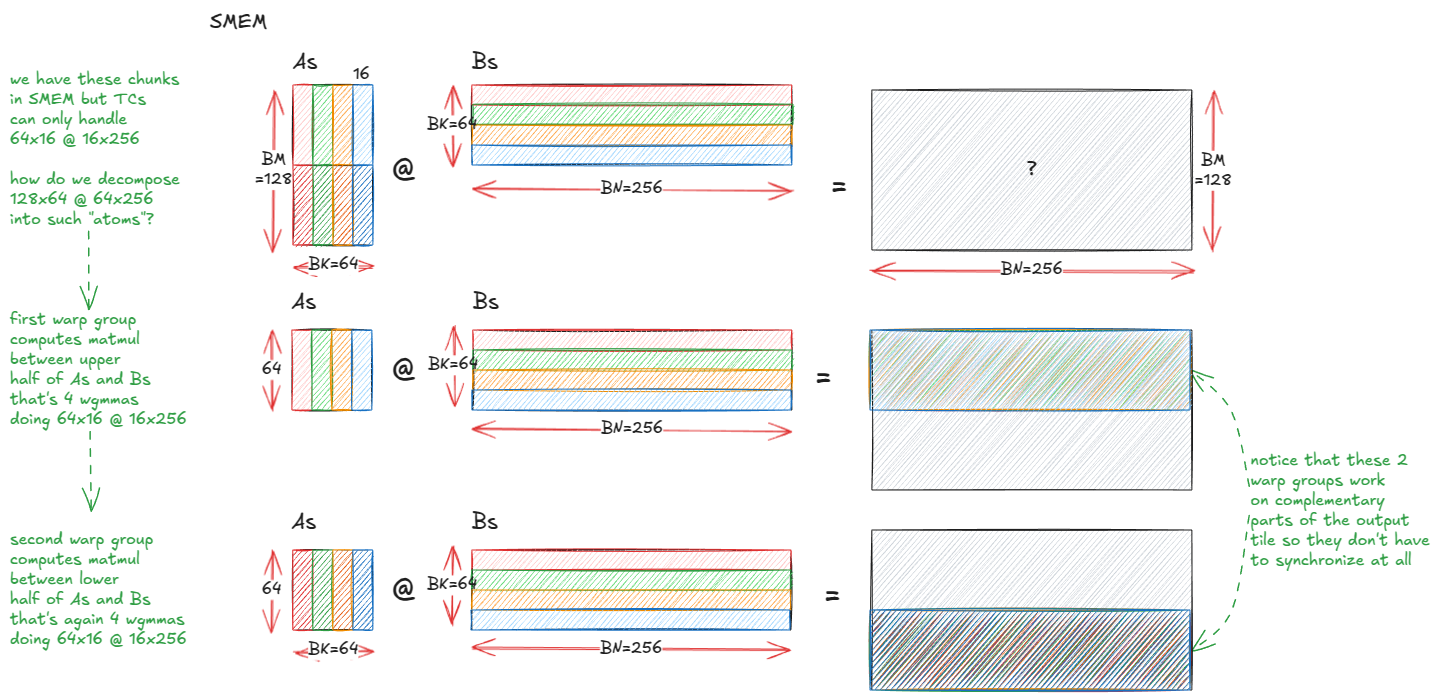
Figure 42: Two consumer warp groups let us grow the tile from 128x128 -> 128x256 without register spills
Figure 42:两个 consumer warp 组让 tile 从 128×128 增大到 128×256,而不会寄存器溢出。
下一个大思路是隐藏输出 tile 写入的延迟:
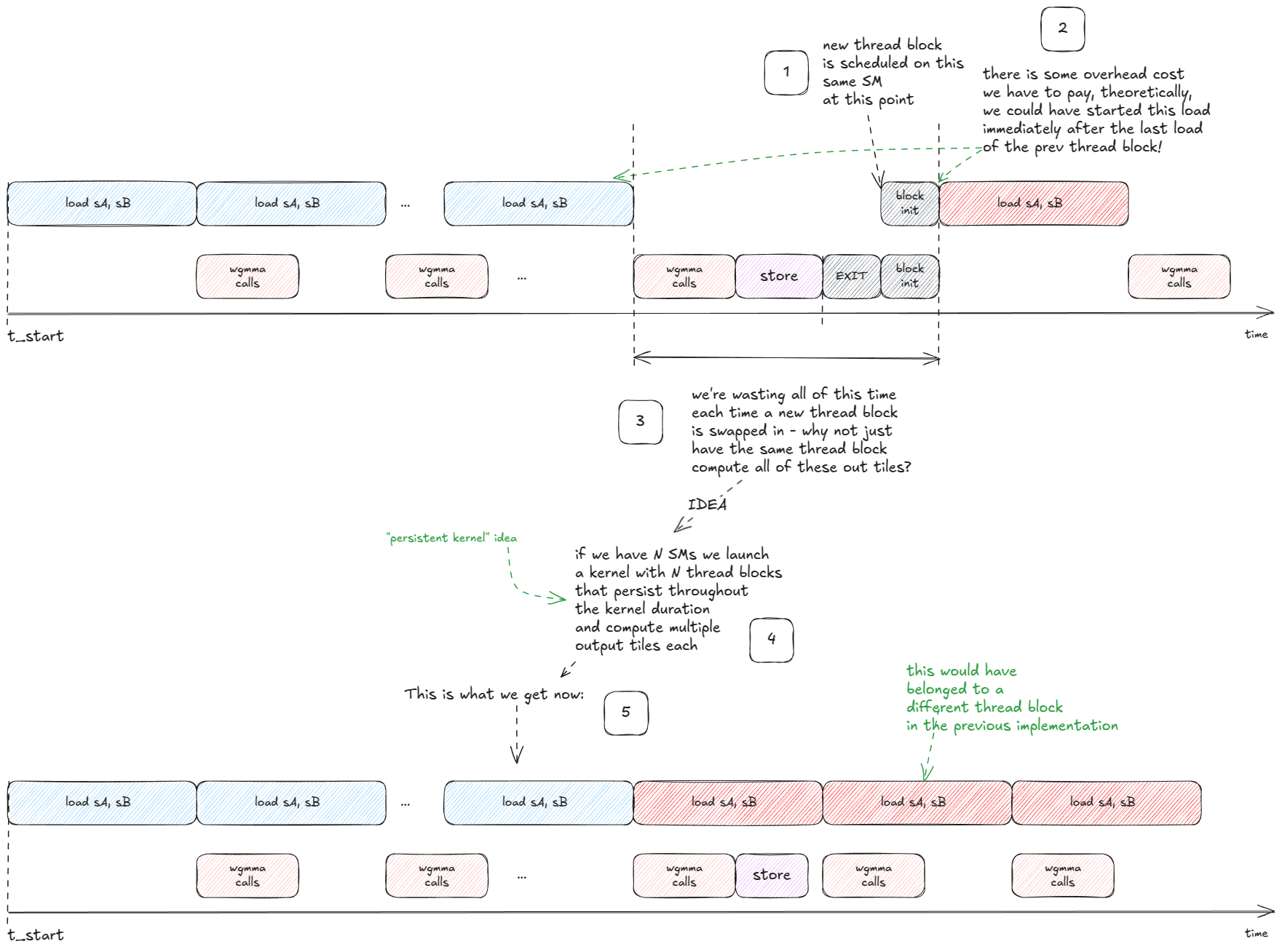
Figure 43: Persistent kernels: overlap the output store with incoming loads by launching one long-lived block per SM that processes many tiles.
Figure 43:持久 kernel:输出写入与输入加载重叠,每个 SM 启动一个长存活块处理多个 tile。
💡持久 kernel 持久 kernel 启动少量固定线程块(通常每个 SM 一个),保持整个工作负载期间存活。每个块运行内部循环,从队列拉取新 tile,直到任务完成,而不是为每个 tile 单独启动块。
这就引出自然问题:每个 SM 应该处理哪些输出 tile,以及处理顺序如何?
调度策略可以这样思考:
- 输出 tile 总数:64
- SM 数量:10
- 每个 SM 平均需处理约 6.4 个块
初步尝试可能如下:
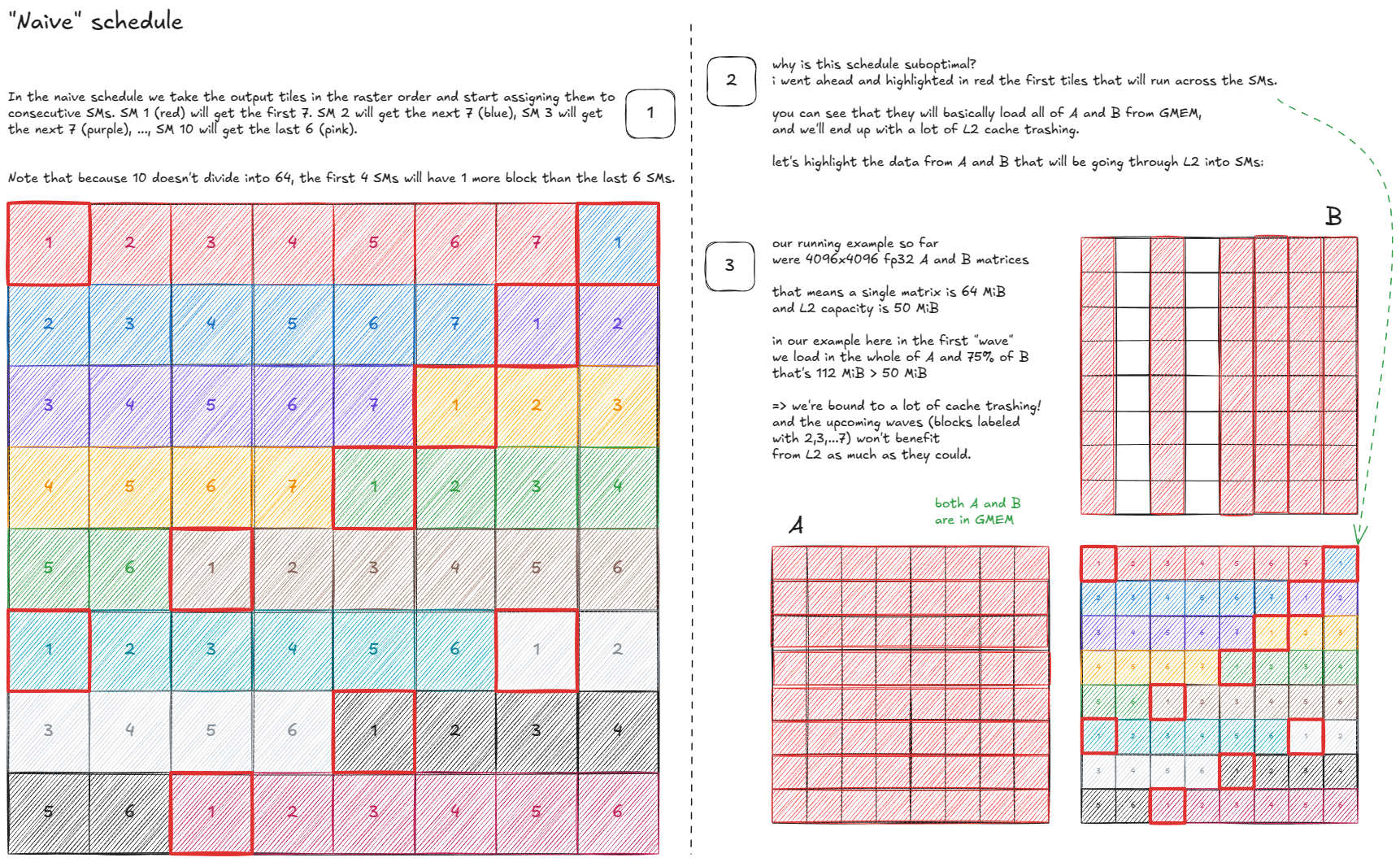
Figure 44: Naïve schedule
Figure 44:初步调度
可以优化吗?可以——通过 cache-aware 调度:
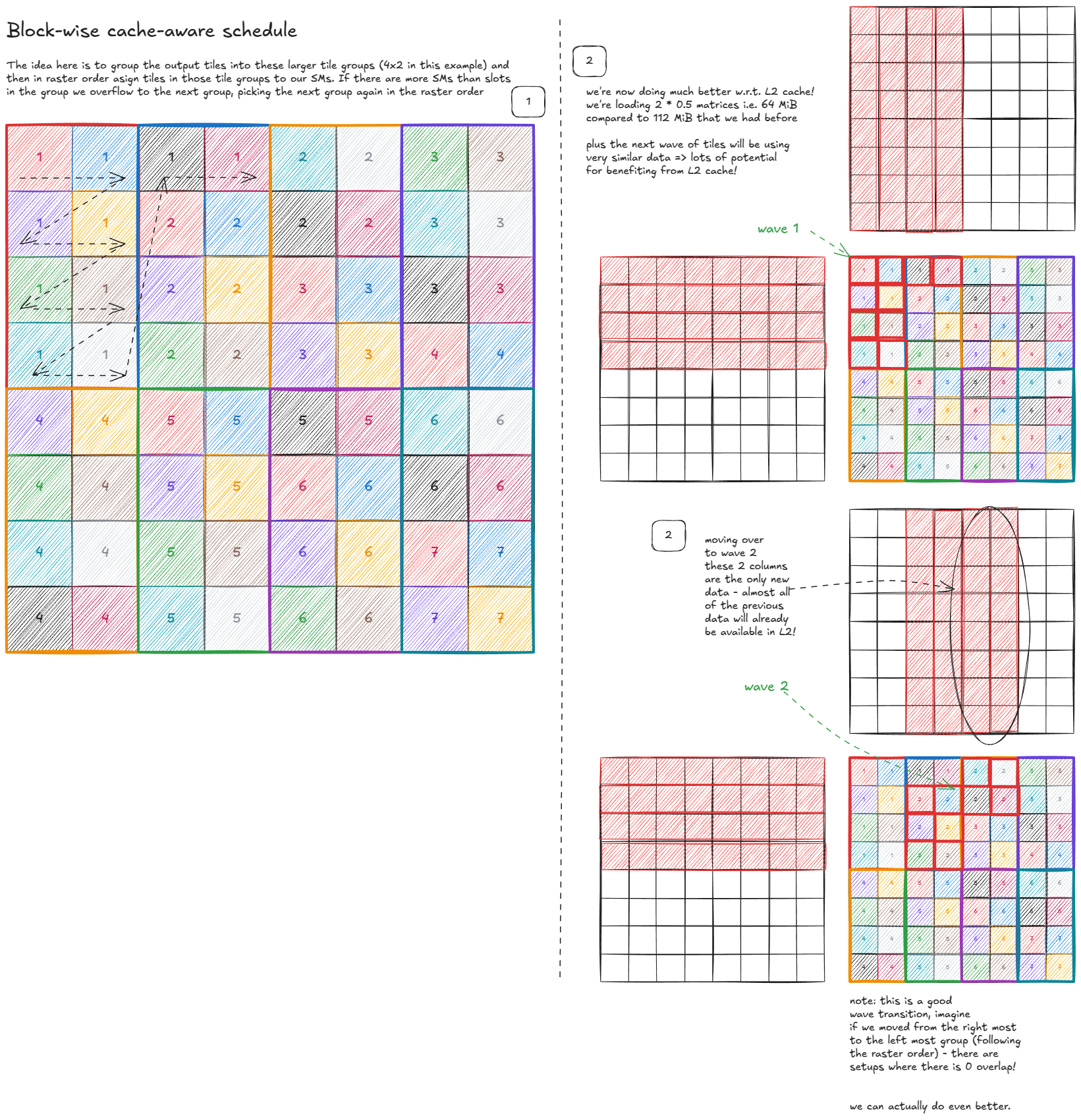
Figure 45: Block-wise cache-aware schedule
Figure 45:块级 cache-aware 调度
还能更优化吗?惊讶地是,可以——使用空间填充曲线:
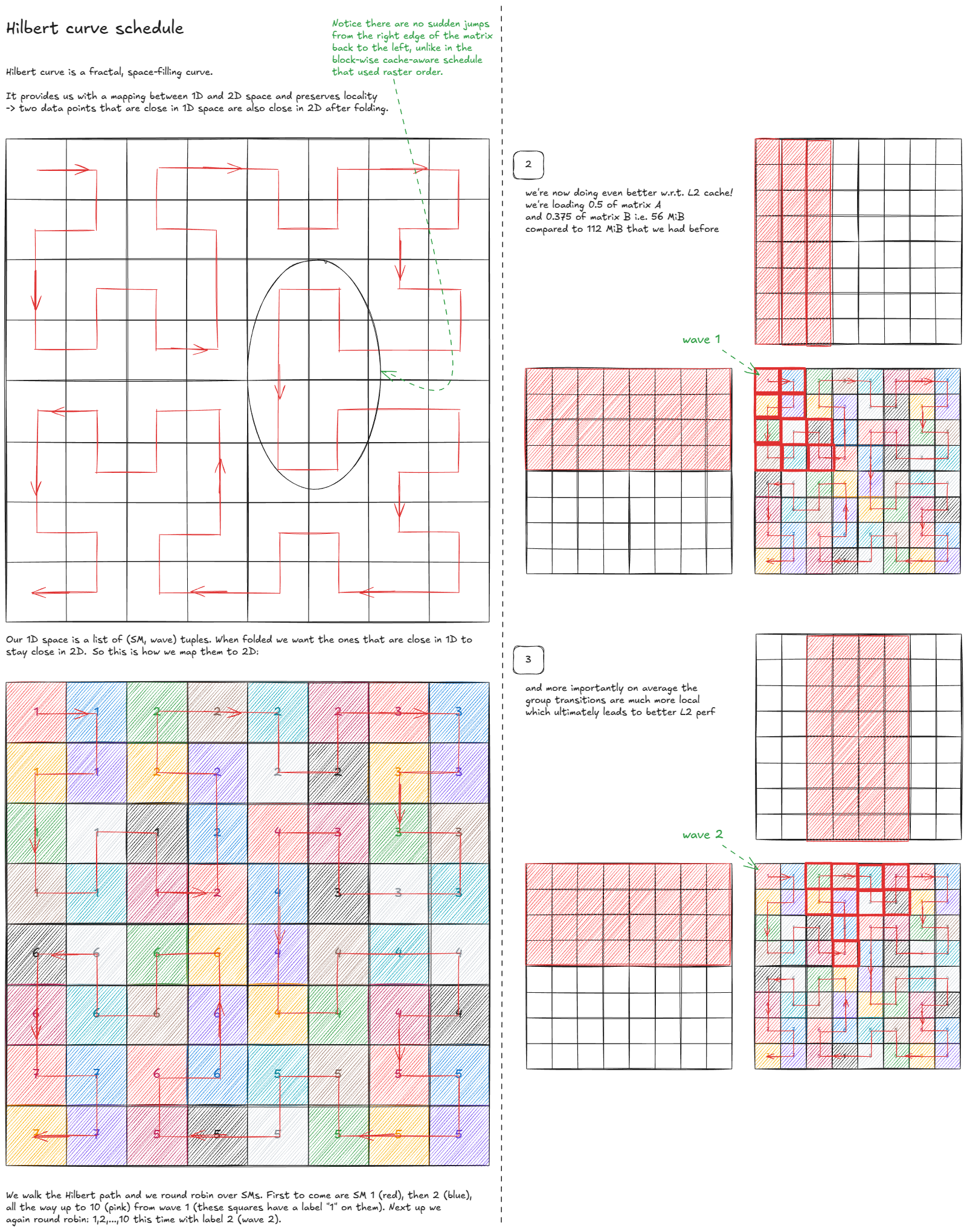
Figure 46: Hilbert-curve schedule
Figure 46:Hilbert 曲线调度
最后一个重点是利用 Hopper 新的 cluster-level CUDA 执行模型,减少 L2/GMEM 访问:
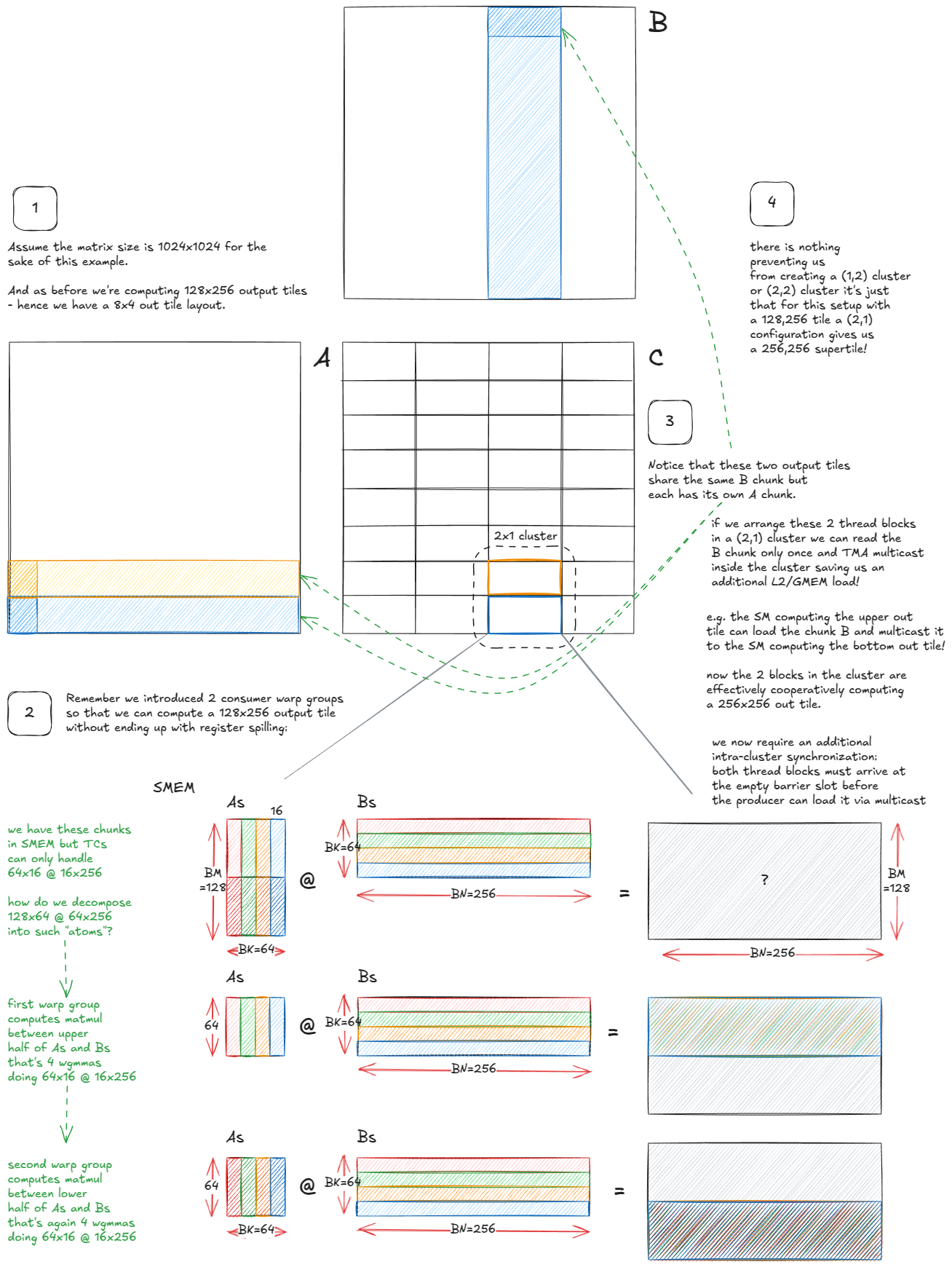
Figure 47: Using thread block clusters to reduce the number of L2/GMEM loads.
Figure 47:利用线程块 cluster 减少 L2/GMEM 访问次数
关键观察:同一 cluster 内的多个 SM 可以直接共享 SMEM(通过 DSMEM),把 cluster 看作一个“超 SM”。
从调度角度看,本质不变:不是每个 SM 独立处理输出 tile,而是整个 cluster 协作处理一个更大的“super-tile”。算法机制不变,但 SM 之间协调加载并复用彼此数据。
Hilbert 曲线遍历本身最大化了局部性,因此 super-SM 也可以沿同样模式,只是粒度更粗。
最后,要超过 cuBLAS,我们必须收紧同步。到此为止,我们在屏障上的 arrive/wait 调用还有浪费。
例如,consumer 线程其实不需要在 full[qidx] 上发信号。关键条件只是“所有字节已到达”。去掉多余的到达信号,每次迭代节省 256 个 token。同样对 empty[qidx]:一旦 consumer 端 tid==0 到达,producer 可以安全开始填充,因为 consumer 端(wgmma)线程是 lock-step 执行的。
一些额外低级优化(实践中累积效应明显,O(NR) 精神):
- 重新分配寄存器:用
asm volatile("setmaxnreg.{inc,dec}.sync.aligned.u32 %0;\n" : : "n"(RegCount));把寄存器预算从轻量 producer warp 组转给 wgmma 重负载的 consumer warp 组。 - 避免输出过程中污染缓存:使用
__stwt绕过 L1/L2,或者更好,异步写:先 spill 到 SMEM,然后让 TMA 异步写回 GMEM,实现写回与计算重叠,就像输入端一样。 - 跳过冗余初始化:不再清零累加器寄存器,而是调整张量核心序列,使首个 MMA 做
C = A @ B,后续 MMA 做C = A @ B + C。
参考性能数据(来自 Pranjal 的博客),显示每个优化在前一项基础上的提升:
| 优化 | 优化前 (TFLOP/s) | 优化后 (TFLOP/s) |
|---|---|---|
| 基线(warp-tiling) → Tensor Cores + TMA | 32 | 317 |
| 增大输出 tile | 317 | 423 |
| 流水线:TMA load 与 TC compute 重叠 | 423 | 498 |
| tile 增长:128×128 → 128×256(2 consumer warp) | 498 | 610 |
| 持久 kernel(隐藏写回延迟) | 610 | 660 |
| 更快的 PTX barrier | 660 | 704 |
| cluster;TMA multicast | 704 | 734 |
| 微优化 | 734 | 747 |
| TMA 异步写(regs → SMEM → GMEM) | 747 | 758 |
| Hilbert 曲线调度 | 758 | 764 |
另外,Aroun 提交了一个 PR,使用 stmatrix 方法优化异步写入,又提升约 1%。一些“核反应堆”被拯救了。
尾声
我们一开始从剖析 GPU 本身入手,重点关注内存层次结构——建立 GMEM、SMEM 和 L1 的心理模型,并将其与 CUDA 编程模型联系起来。在此过程中,我们还观察了“光速”的限制,以及功耗如何对性能设限——硬件现实不可避免地渗透进我们的模型中。
接着,我们上升到软件栈层面:学习如何通过 PTX/SASS 与硬件沟通,以及如何引导编译器生成我们真正想要的代码。
沿途我们掌握了关键概念——tile 与 wave 量化、occupancy、ILP、roofline 模型——并围绕基本等价性建立直觉:点积可以看作部分外积的累和,或部分点积的累和,以及为什么方形 tile 会产生更高的算术强度。
在此基础上,我们构建了接近 SOTA 的内核(warp tiling),用 CUDA 核心、寄存器和共享内存挤出极致性能。
最后,我们踏入了 Hopper 的世界:TMA、swizzling、张量核心与 wgmma 指令、异步 load/store 流水线、Hilbert 曲线等调度策略、配合 TMA multicast 的 cluster、更快的 PTX barrier,以及更多高级优化。
我想以一句贯穿整个系列的信念收尾:计算机是可以被理解的。
致谢
特别感谢 Hyperstack 在过去一年中提供的 H100 支持我的实验。
感谢我的朋友 Aroun Demeure(Magic 的 GPU & AI,前 Apple 和 Imagination GPU 架构师)和 Mark Saroufim(PyTorch),阅读本文预发布版本并提供宝贵反馈。
订阅即可在我发布新文章时获得通知。
subscribe
参考文献
- NVIDIA Hopper Architecture In-Depth https://developer.nvidia.com/blog/nvidia-hopper-architecture-in-depth/
- NVIDIA Ampere Architecture In-Depth https://developer.nvidia.com/blog/nvidia-ampere-architecture-in-depth/
- Strangely, Matrix Multiplications on GPUs Run Faster When Given “Predictable” Data! [short] https://www.thonking.ai/p/strangely-matrix-multiplications
- How CUDA Programming Works https://www.nvidia.com/en-us/on-demand/session/gtcfall22-a41101/
- Notes About Nvidia GPU Shared Memory Banks https://feldmann.nyc/blog/smem-microbenchmarks
- CUDA Binary Utilities https://docs.nvidia.com/cuda/cuda-binary-utilities/index.html
- Lecture 37: Introduction to SASS & GPU Microarchitecture https://www.youtube.com/watch?v=we3i5VuoPWk
- Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking https://arxiv.org/abs/1804.06826
- How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance: a Worklog https://siboehm.com/articles/22/CUDA-MMM
- CUDA C programming guide https://docs.nvidia.com/cuda/cuda-c-programming-guide/
- Lecture 44: NVIDIA Profiling https://www.youtube.com/watch?v=F_BazucyCMw&ab_channel=GPUMODE
- https://github.com/siboehm/SGEMM_CUDA/
- CUTLASS: Fast Linear Algebra in CUDA C++ https://developer.nvidia.com/blog/cutlass-linear-algebra-cuda/
- Efficient GEMM in CUDA https://github.com/NVIDIA/cutlass/blob/b0e09d7cd371eded41f7c1e057caf1593c27ba55/media/docs/efficient_gemm.md
- Outperforming cuBLAS on H100: a Worklog https://cudaforfun.substack.com/p/outperforming-cublas-on-h100-a-worklog
- Deep Dive on CUTLASS Ping-Pong GEMM Kernel https://pytorch.org/blog/cutlass-ping-pong-gemm-kernel/
- https://github.com/pranjalssh/fast.cu/
- Understanding CuTe Swizzling - The Math Behind 32B, 64B, and 128B Patterns https://veitner.bearblog.dev/understanding-cute-swizzling-the-math-behind-32b-64b-and-128b-patterns/
- Parallel Thread Execution https://docs.nvidia.com/cuda/parallel-thread-execution/index.html
- Inline PTX Assembly in CUDA https://docs.nvidia.com/cuda/inline-ptx-assembly/
- Demystifying the Characteristics of High Bandwidth Memory for Real-Time Systems https://upcommons.upc.edu/server/api/core/bitstreams/b843de39-f32f-4069-8843-48f74c030213/content
- https://github.com/triton-lang/triton